
TeD-Loc: Text Distillation for Weakly Supervised Object Localization (2025)
by Shakeeb Murtaza1, Soufiane Belharbi1, Marco Pedersoli1, Eric Granger1
1 LIVIA, ILLS, Dept. of Systems Engineering, ETS Montreal, Canada
![]()
![]()
@article{murtaza24tedloc,
title="{TeD-Loc}: Text Distillation for Weakly Supervised Object Localization",
author="Murtaza, S. and Belharbi, S. and Pedersoli, M. and Granger, E.",
journal="CoRR",
volume="abs/2501.12632",
year="2025"
}
Abstract
Weakly supervised object localization (WSOL) using classification models trained with only image-class labels remains an important challenge in computer vision. Given their reliance on classification objectives, traditional WSOL methods like class activation mapping focus on the most discriminative object parts, often missing the full spatial extent. In contrast, recent WSOL methods based on vision-language models like CLIP require ground truth classes or external classifiers to produce a localization map, limiting their deployment in downstream tasks. Moreover, methods like GenPromp attempt to address these issues but introduce considerable complexity due to their reliance on conditional denoising processes and intricate prompt learning. This paper introduces Text Distillation for Localization (TeD-Loc), an approach that directly distills knowledge from CLIP text embeddings into the model backbone and produces patch-level localization. Multiple instance learning of these image patches allows for accurate localization and classification using one model without requiring external classifiers. Such integration of textual and visual modalities addresses the longstanding challenge of achieving accurate localization and classification concurrently, as WSOL methods in the literature typically converge at different epochs. Extensive experiments show that leveraging text embeddings and localization cues provides a cost-effective WSOL model. TeD-Loc improves Top-1 Loc accuracy over state-of-the-art models by about 5% on both CUB and ILSVRC datasets, while significantly reducing computational complexity compared to GenPromp. Our code can be accessed at: https://github.com/shakeebmurtaza/TeDLOC.
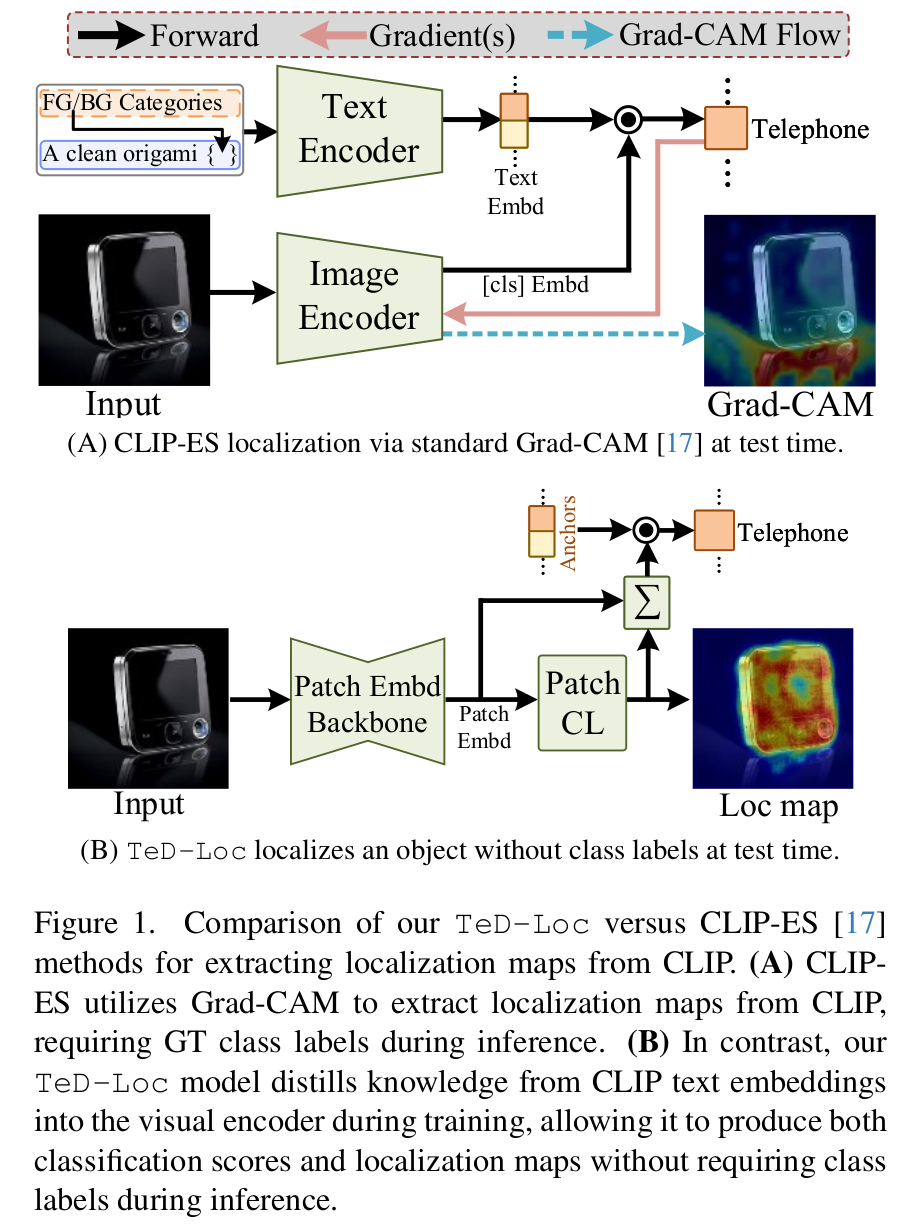
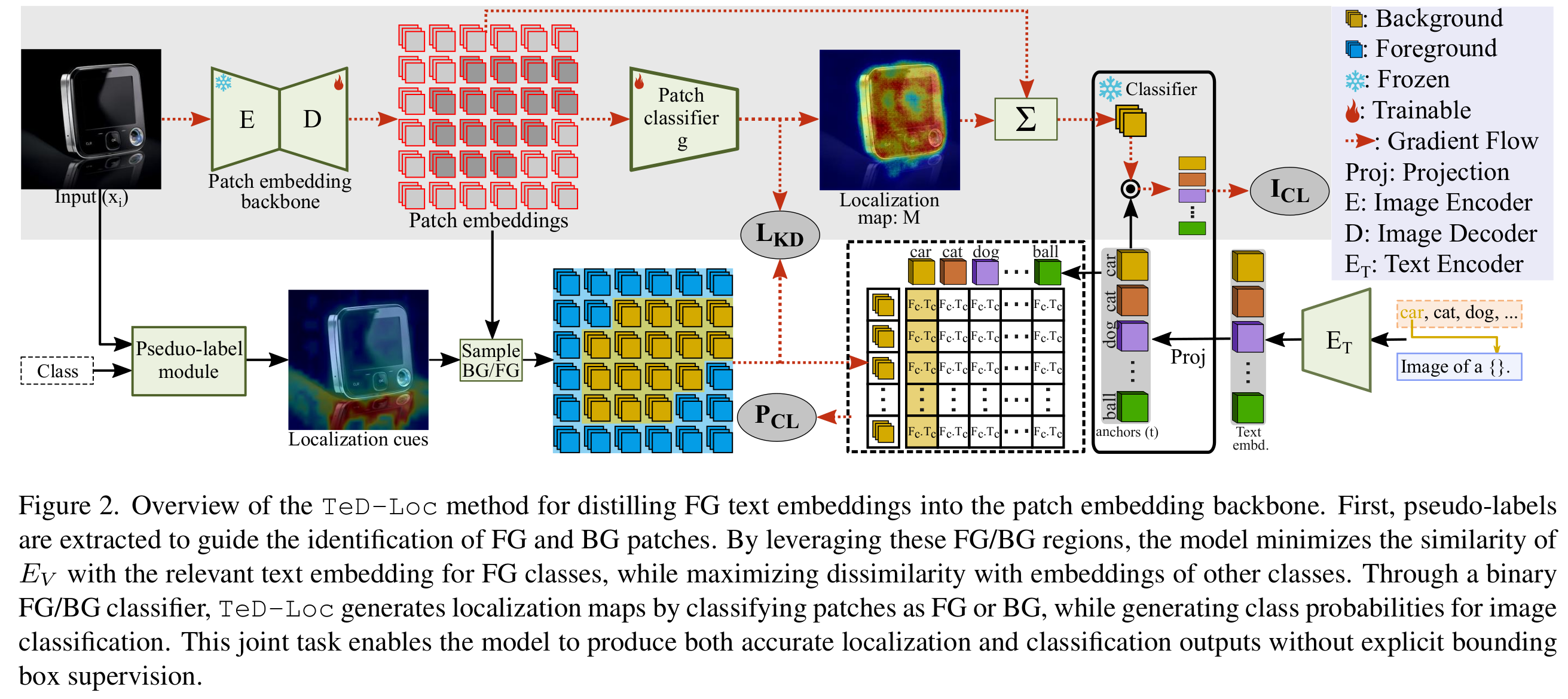
The Proposed Method
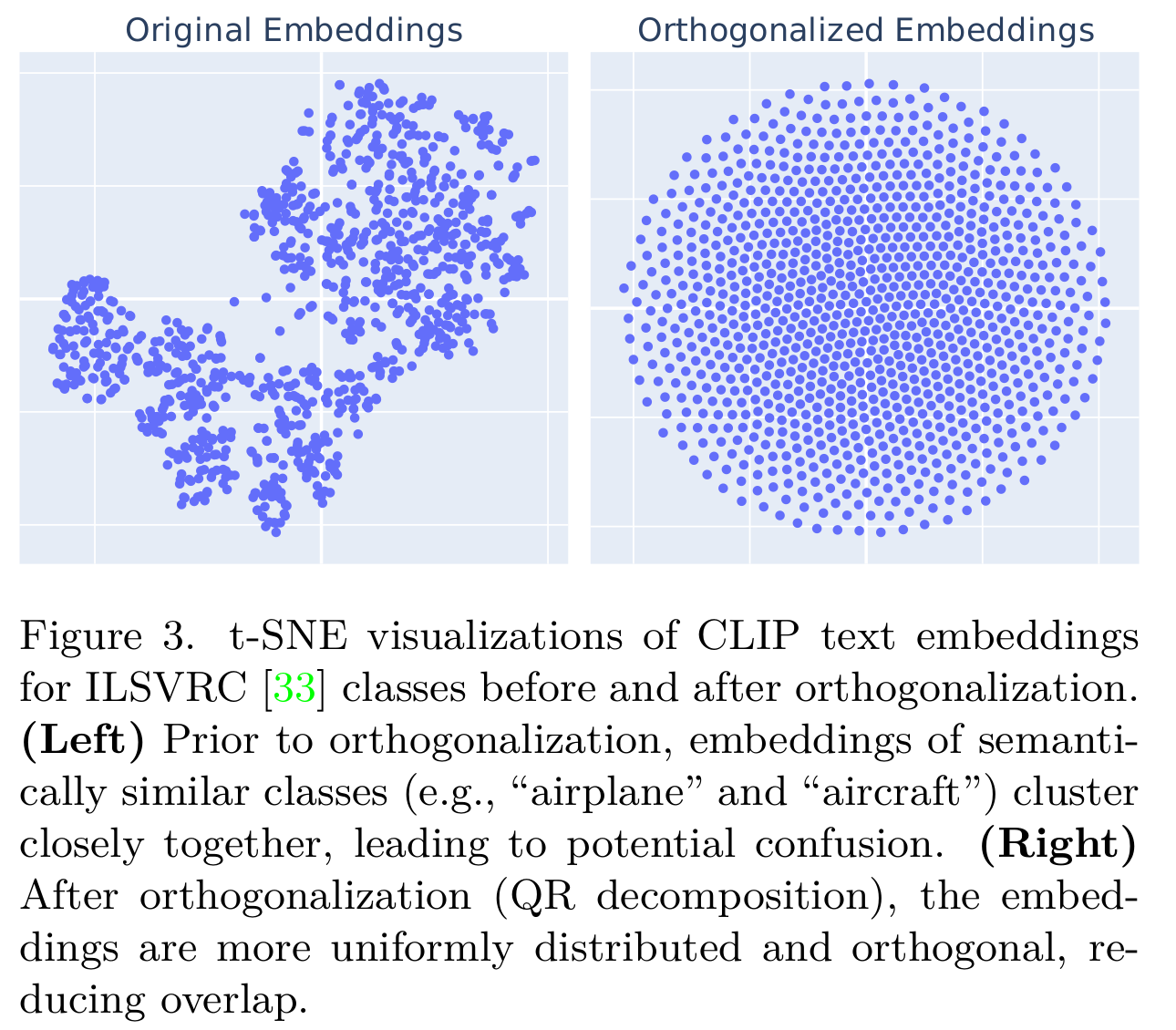
Text embeddings orthogonalization
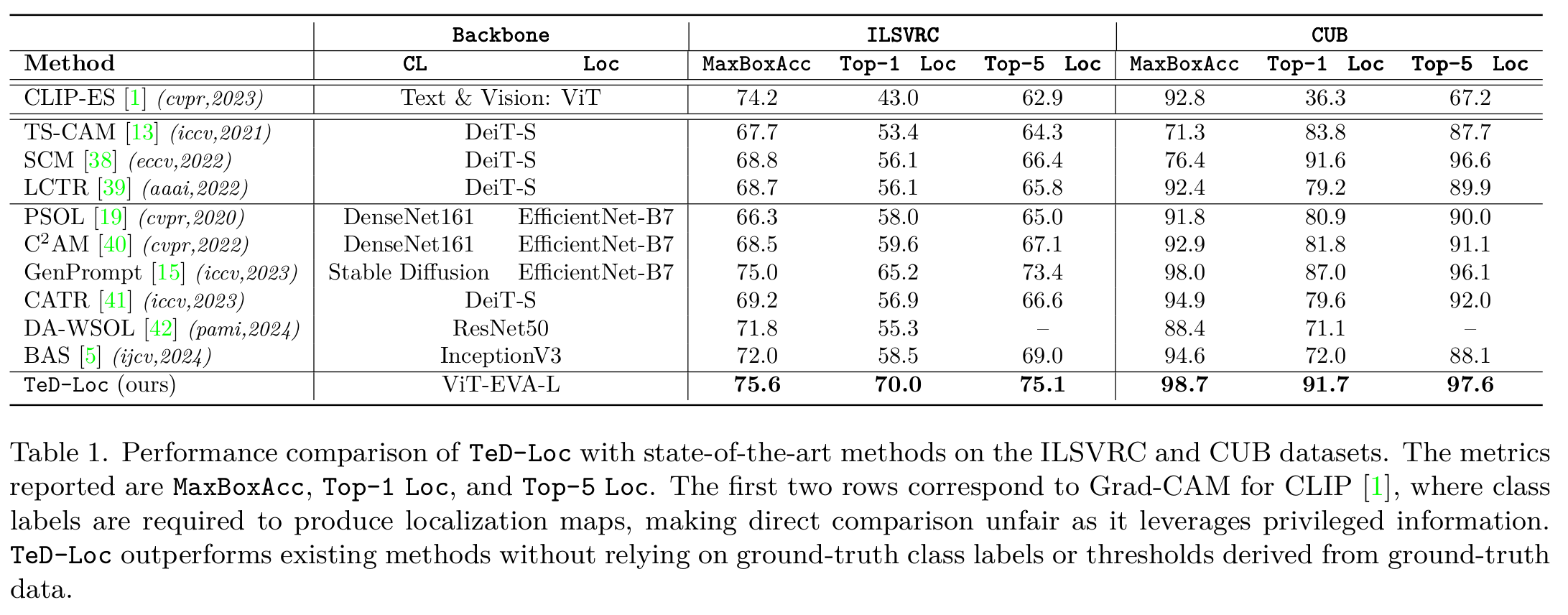
Results
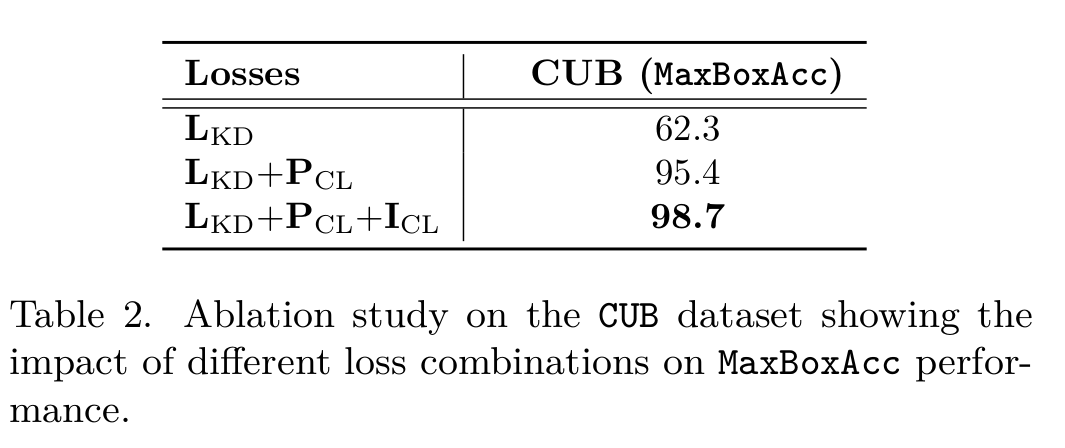
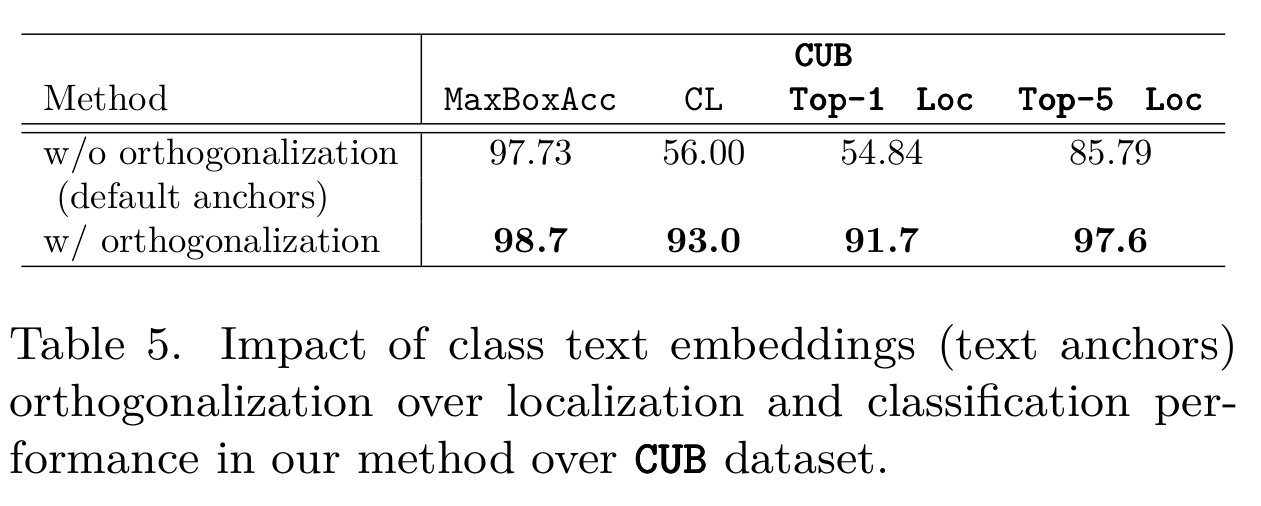
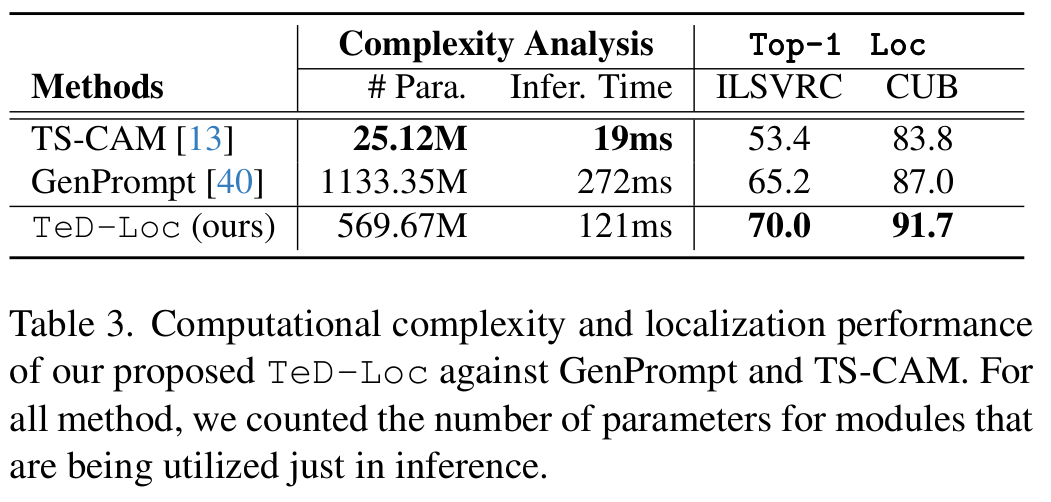
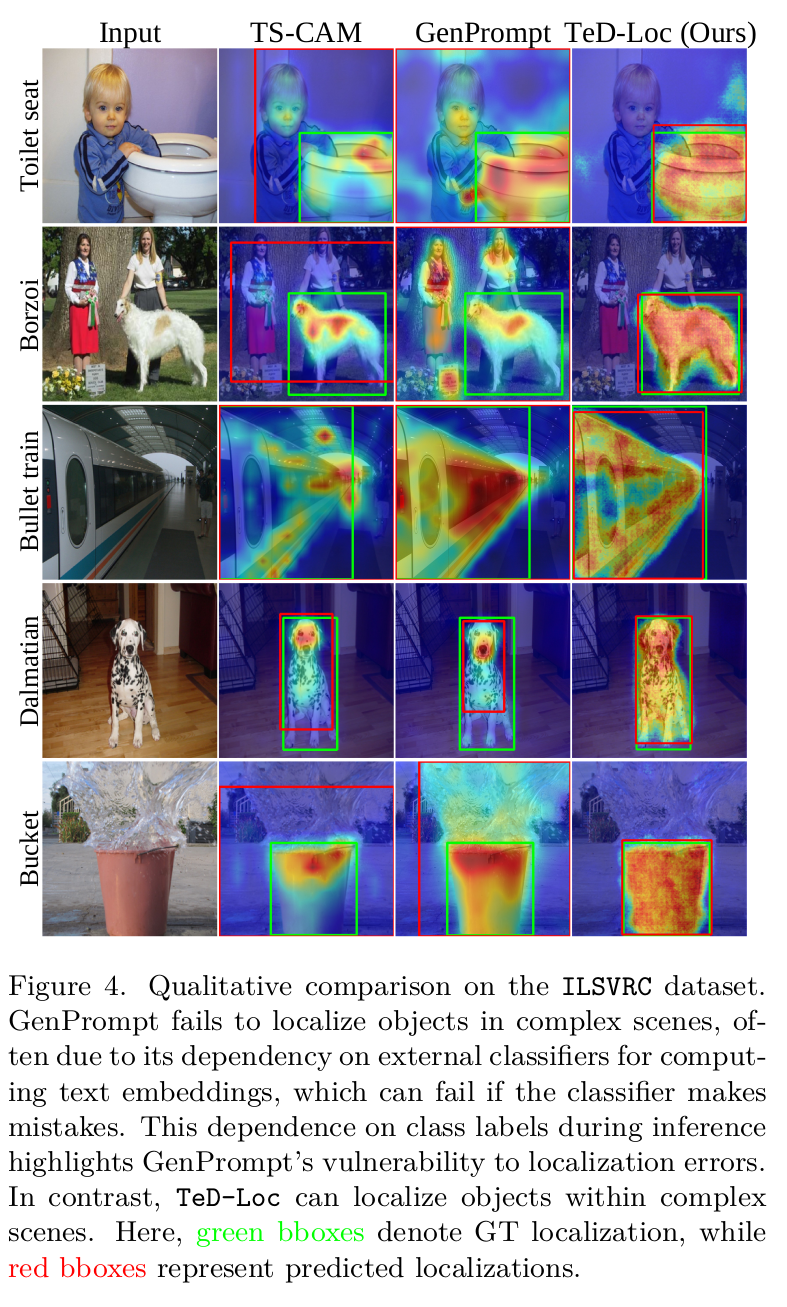
Conclusion
We have introduced TeD-Loc, a novel approach that integrates textual and visual modalities by transferring knowledge directly from CLIP’s text embeddings to our patch embedding module. This alignment enables our model to localize objects at the patch-level while simultaneously performing classification. TeD-Loc exemplifies how the fusion of language and visual information can help in WSOL, demonstrating that classification can be achieved through localization, we discover that bridging modalities is not only feasible but also beneficial for complex vision tasks. Future research could explore deeper integrations of multimodal embeddings and extend this framework to other domains requiring weak supervision.
Acknowledgments
This research was supported in part by the Natural Sciences and Engineering Research Council of Canada, and the Digital Research Alliance of Canada.