
A Realistic Protocol for Evaluation of Weakly Supervised Object Localization (WACV2025)
by Shakeeb Murtaza1, Soufiane Belharbi1, Marco Pedersoli1, Eric Granger1
1 LIVIA, ILLS, Dept. of Systems Engineering, ETS Montreal, Canada
![]()
![]()
@inproceedings{murtaza25realistic,
title = {A Realistic Protocol for Evaluation of Weakly Supervised Object Localization},
author = {Murtaza, S. and Belharbi, S. and Pedersoli, M. and Granger, E.},
booktitle= {WACV},
year = {2025},
}
Abstract
Weakly Supervised Object Localization (WSOL) allows training deep learning models for classification and localization (LOC) using only global class-level labels. The absence of bounding box (bbox) supervision during training raises challenges in the literature for hyper-parameter tuning, model selection, and evaluation. WSOL methods rely on a validation set with bbox annotations for model selection, and a test set with bbox annotations for threshold estimation for producing bboxes from localization maps. This approach, however, is not aligned with the WSOL setting as these annotations are typically unavailable in real-world scenarios. Our initial empirical analysis shows a significant decline in LOC performance when model selection and threshold estimation rely solely on class labels and the image itself, respectively, compared to using manual bbox annotations. This highlights the importance of incorporating bbox labels for optimal model performance. In this paper a new WSOL evaluation protocol is proposed that provides LOC information without the need for manual bbox annotations. In particular, we generated noisy pseudo-boxes from a pretrained off-the-shelf region proposal method such as Selective Search, CLIP, and RPN for model selection. These bboxes are also employed to estimate the threshold from LOC maps, circumventing the need for test-set bbox annotations. Our experiments with several WSOL methods on challenging natural and medical image datasets show that using the proposed pseudo-bboxes for validation facilitates the model selection and threshold estimation, with LOC performance comparable to models selected using GT bboxes on the validation set and threshold estimation on the test set. It also outperforms models selected using class-level labels, and then dynamically thresholded with only LOC maps. Our code and generated pseudo-bounding boxes can be accessed at: github.com/shakeebmurtaza/wsol_model_selection.
A Realistic Protocol for Model Evaluation
In this section, we describe a new protocol for evaluating WSOL methods. First LOC accuracy is shown to be overestimated when using manual bbox supervision for the held-out validation set. To address this, automatically generating pseudo-bboxes is proposed for the validation set using only class-label supervision, eliminating the need for manual annotation. It involves generating pseudo-bboxes for the validation set using off-the-shelf ROI proposal generators and utilizing these pseudo-bboxes to estimate a threshold. Then this can be applied to localization maps in the test set for producing bboxes, providing a more systematic and realistic evaluation protocol.
Model Selection
Consider a WSOL training set \({\mathcal{D}_{train}=\{(x_i, y_i, \cdot)\}}\) composed of samples with \({x_i}\) the input image, \({y_i}\) its class-label, and \({\cdot}\) is its missing bbox supervision. Let us define \({\mathcal{D}_{val}=\{(x_i, y_i, \cdot)\}_{i=1}^N}\), and \({\mathcal{D}_{test}=\{(x_i, y_i, o(x_i))\}}\) as the held-out validation and test sets, respectively, where \({o(x_i)}\) is the oracle manual bbox annotation for the sample \({x_i}\). In the WSOL setting, bbox supervision is unavailable for any dataset. However, in a laboratory, the test set contains them to evaluate localization performance of a model.
The WSOL setting involves training a model \({f(\cdot; \theta)}\) with parameters \({\theta}\) to correctly classify an input image while yielding LOC boxes. Training is performed on \({\mathcal{D}_{train}}\) that lacks LOC supervision. In this paper, we introduce a pseudo-annotator \({\hat{o}}\) that automatically annotates an image with pseudo-bboxes (without human intervention) and only requires the class-labels. \({\hat{o}}\) yields noisy bboxes, providing LOC pseudo-bbox annotations \({\hat{o}(x_i)}\) that are less accurate than oracle bbox annotations \({o(x_i)}\). Moreover, we redefine the validation set \(\mathcal{D}_{val}\) to incorporate pseudo-bboxes \({\hat{o}(x_i)}\), yielding \({\mathcal{D}_{val}=\{(x_i, y_i, {\hat{o}(x_i)})\}_{i=1}^N}\).
Let \({f(x;\theta)}\) be the model’s classification prediction, while \({f(x;\theta)^b}\) is the predicted bbox for image \(x\). We denote by \({\ell(\cdot, \cdot)}\) a localization similarity measure between two bboxes. Following Choe et al., \({\ell(\cdot, \cdot)}\) is commonly MaxBoxAcc or simply the Intersection-Over-Union (IOU) measure. Let us define a hypothetical ideal scenario where one can have access to the oracle for fully annotated bboxes \({o(x_i)}\) in the validation set \({\mathcal{D}_{val}}\) allowing, for instance, to perform early stopping and threshold selection. Therefore, we can define the average localization performance of the model \(f\) with a specific parameter value of \(\theta\) over this validation set as,
\begin{equation} \label{wacveval:eq:vl_exact_sup} \mathcal{M}(\theta, \mathcal{D}_{val})_o = \frac{1}{N} \sum_i^N \ell(f(x_i;\theta)^b, o(x_i)). \end{equation}
Similarly, the same measure over \({\mathcal{D}_{val}}\) can be defined using our pseudo-annotator \({\hat{o}}\) as,
\begin{equation} \label{wacveval:eq:vl_noisy_sup} \mathcal{M}(\theta, \mathcal{D}_{val})_{\hat{o}} = \frac{1}{N} \sum_i^N \ell(f(x_i;\theta)^b, \hat{o}(x_i)). \end{equation}
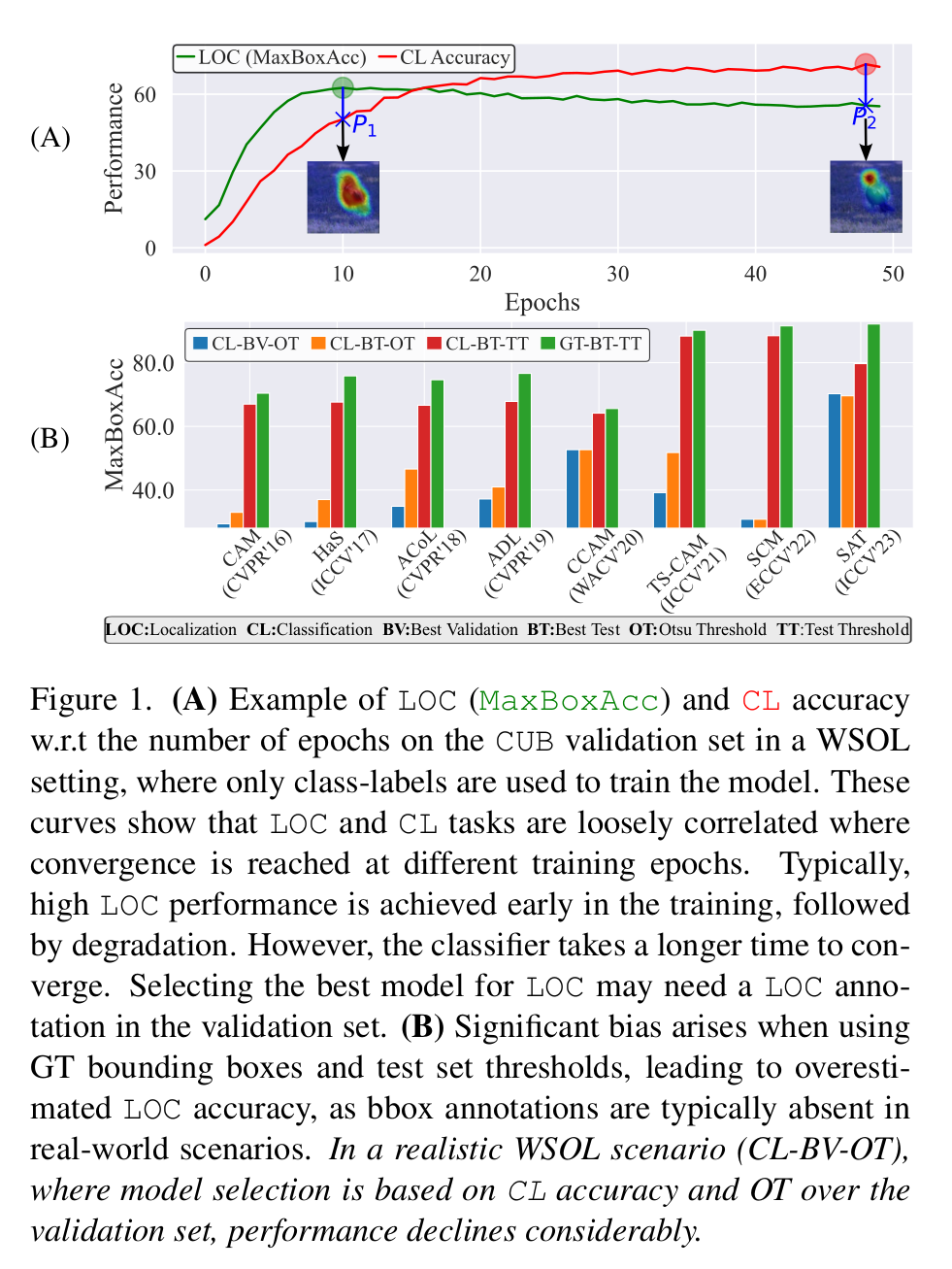
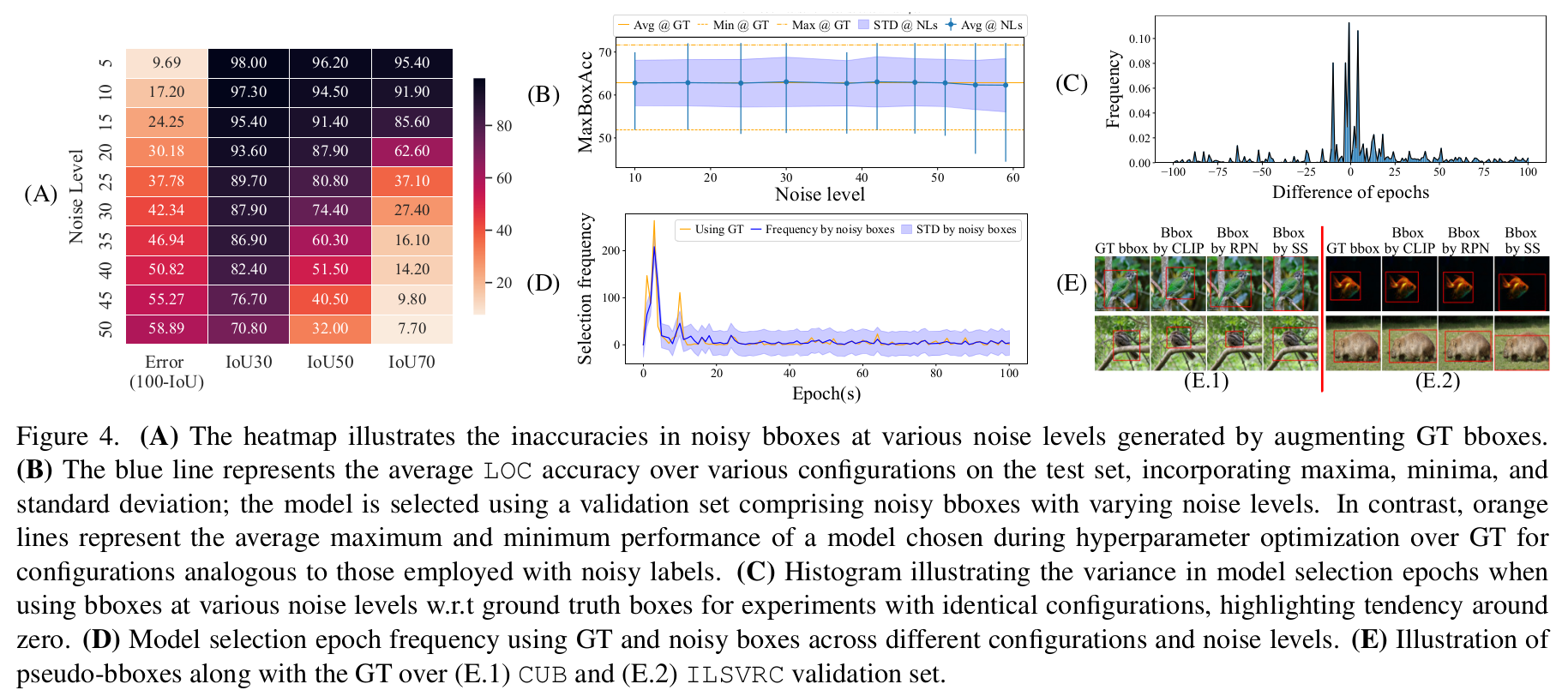
Eqs. \eqref{wacveval:eq:vl_exact_sup} and \eqref{wacveval:eq:vl_noisy_sup} provide an assessment of the model localization accuracy over a held-out \({\mathcal{D}_{val}}\). Eq.\ref{wacveval:eq:vl_exact_sup} is accurate, while Eq.\ref{wacveval:eq:vl_noisy_sup} accounts for errors due to inaccurate localization annotation. Since practitioners do not have access to the oracle bboxes ${o(x_i)}$, the measure \({\mathcal{M}(\theta, \mathcal{D}_{val})_o}\) is not realistic. When one has access to oracle ${o(x_i)}$ bboxes for training, it is better to perform SSL to directly fit the model weights instead of WSOL. However, one can still assess \({\mathcal{M}(\theta, \mathcal{D}_{val})_{\hat{o}}}\) for an approximate but realistic estimation of the model’s localization accuracy. The latter measure provides a realistic assessment of localization accuracy for WSOL. A direct application of our proposed noisy measure \({\mathcal{M}(\theta, \mathcal{D}_{val})_{\hat{o}}}\) in the WSOL setting is early stopping for model selection, and hyper-parameter search. In these applications, the measure must follow a similar behaviour to \({\mathcal{M}(\theta, \mathcal{D}_{val})_o}\), as shown in the next figure.
Pseudo-bbox Annotation
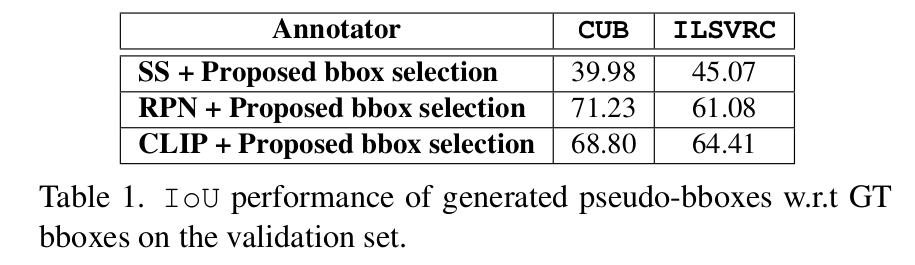
For generation of pseudo-bboxes (using \({\hat{o}}\)), we leverage pretrained of-the-shelf region proposal models to generate LOC annotations for a held-out validation set \({\mathcal{D}_{val}=\{(x_i, y_i, {\hat{o}(x_i)})\}_{i=1}^N}\). This set is originally labeled with class-labels only. These models can be unsupervised without the need for training or require weak supervision for training. We consider the three following scenarios of the pretrained model depending on its level of supervision.
-
Unsupervised: In this case, the model does not have access to any supervision. Typical examples are conventional region proposal methods that are generally used to build pseudo-supervision to train object detector models. Selective Search (SS) is a commonly used method where no parameters are learned. Carefully engineered features and score functions are used to greedily merge low-level superpixels that produce the final region proposals. The per-proposal score can be used to rank the likelihood that the proposal contains an object.
-
Supervised with class-labels: A middle-ground approach is to use class-labels which are available in the WSOL setting. The CLIP model is a model trained on millions of generic text-image pairs from the Internet. Pretrained CLIP is used to pseudo-annotate our held-out. Class labels are used as a prompt to generate a CAM for the labeled object in the image. The CAM is automatically thresholded using the Otsu method. Then, a bbox is constructed around each connected object. Since CLIP points to the discriminative region associated with the input class-label, we select the largest bbox as a pseudo-bbox.
-
Supervised with class agnostic bboxes: An alternative approach involves using a region proposal model that is trained using a general dataset like Pascal VOC and MS-COCO, with LOC bboxes. This methodology differs in that it does not employ class-labels, but rather LOC bboxes that are class-agnostic. A typical example is the RPN, a fully convolutional network that simultaneously predicts object bounds at each position, and provides objectness scores that allow to rank proposals.
For SS and RPN several bboxes are generated per image. To discard irrelevant bboxes and select the most discriminative one, we leverage the pointing game analysis. To this end, a classifier pretrained over \(\mathcal{D}_{train}\) is considered. It is trained until convergence using only class-labels. The pointing game uses the maximum CAM response to select the most discriminative bboxes. In the case where multiple bboxes are ultimately selected, they are scored by the classifier response, and the bbox with the highest score is ultimately selected. Pseudo-bbox annotations are constructed for \({\mathcal{D}_{val}}\), where each box contains the most discriminative object labeled in the image. This process is only executed once before performing any WSOL training. The generated bboxes are stored on disk, and used for future WSOL training. Therefore, our approach does not add any computation time to the training itself.
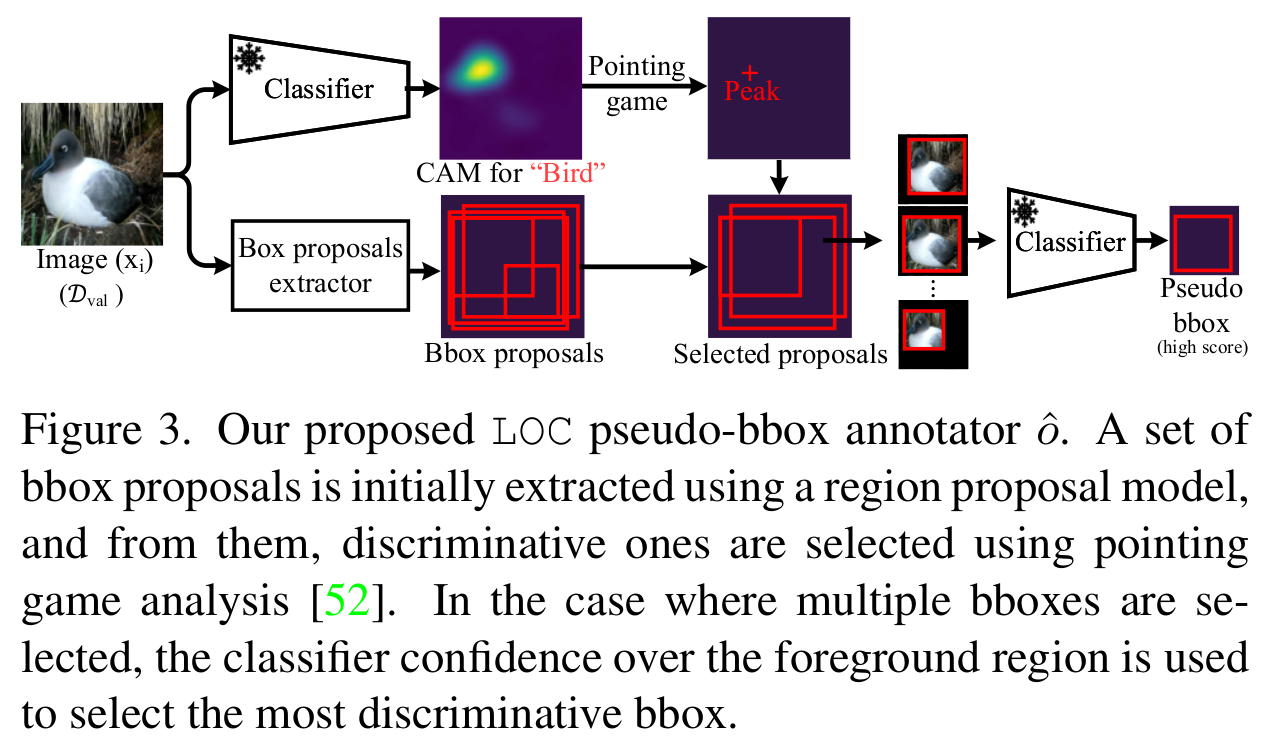
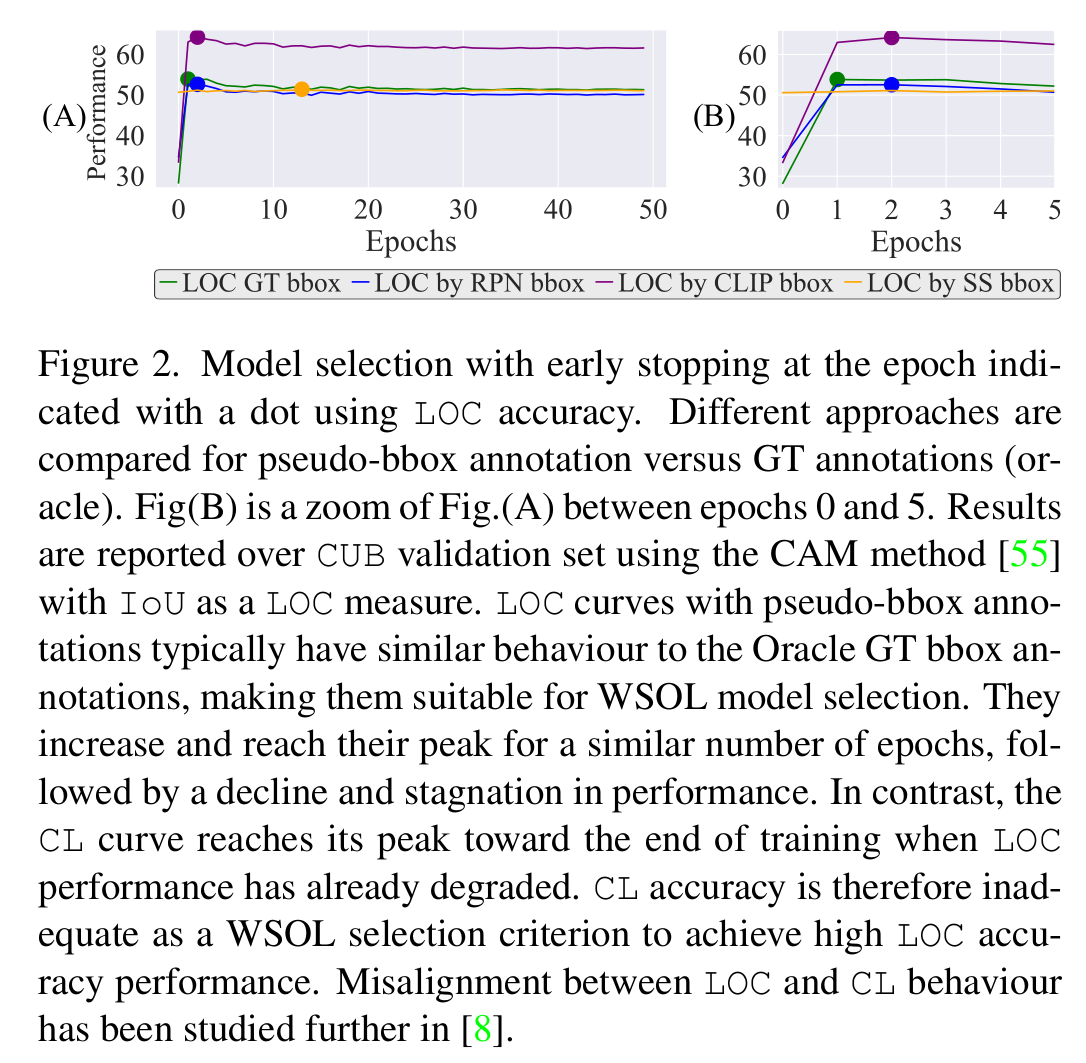
Fig.2 shows the behaviour of localization performance when using pseudo-bboxes vs oracle bboxes over \({\mathcal{D}_{val}}\). The overall trend is similar as they both increase during the first epochs and reach their peak, decline and stagnate over the following epochs. This is extremely helpful for early stopping and hyper-parameter search. We also observe that localization using CLIP pseudo-annotation yields higher localization than the with the oracle. This is plausible since a model prediction can be further aligned with some annotations than others.
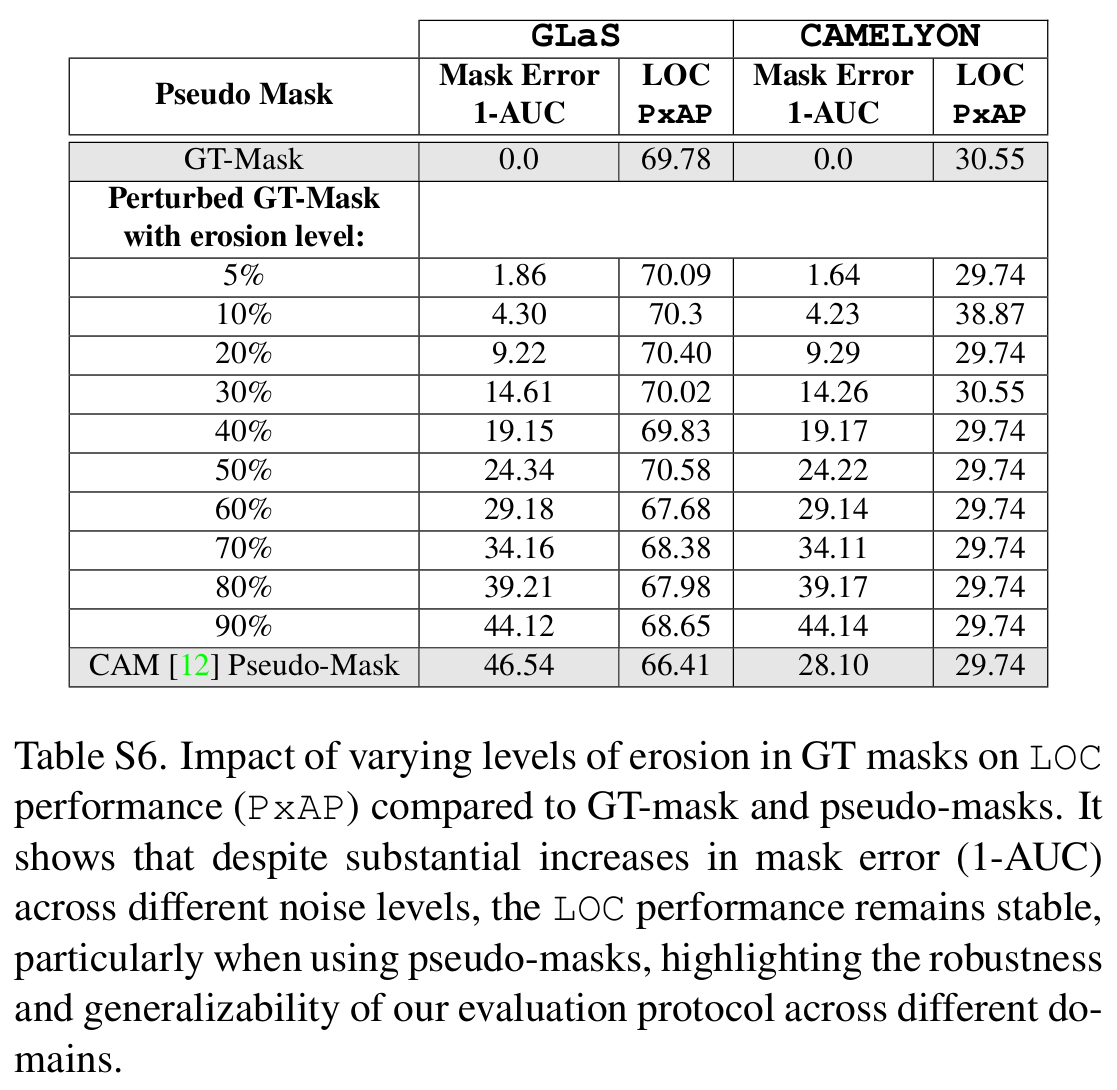
To provide a realistic evaluation protocol for WSOL, we proposed a strategy to generate pseudo-bboxes for \({\mathcal{D}_{val}}\). It bypasses the need for manually annotated (oracle) bboxes by leveraging pretrained region proposal models. Then, the pointing game analysis is used to select the most discriminative proposals. In our results, we show that using manually annotated bboxes for \({\mathcal{D}_{val}}\) set can increase localization accuracy on \({\mathcal{D}_{test}}\), leading to performance overestimation. We also show that noisy pseudo-bboxes can effectively be used for model selection in the WSOL. This is initially shown using synthetic boxes, then using our generated pseudo-bboxes. These pseudo-bboxes are made public to the researchers for the design of more realistic WSOL methods.
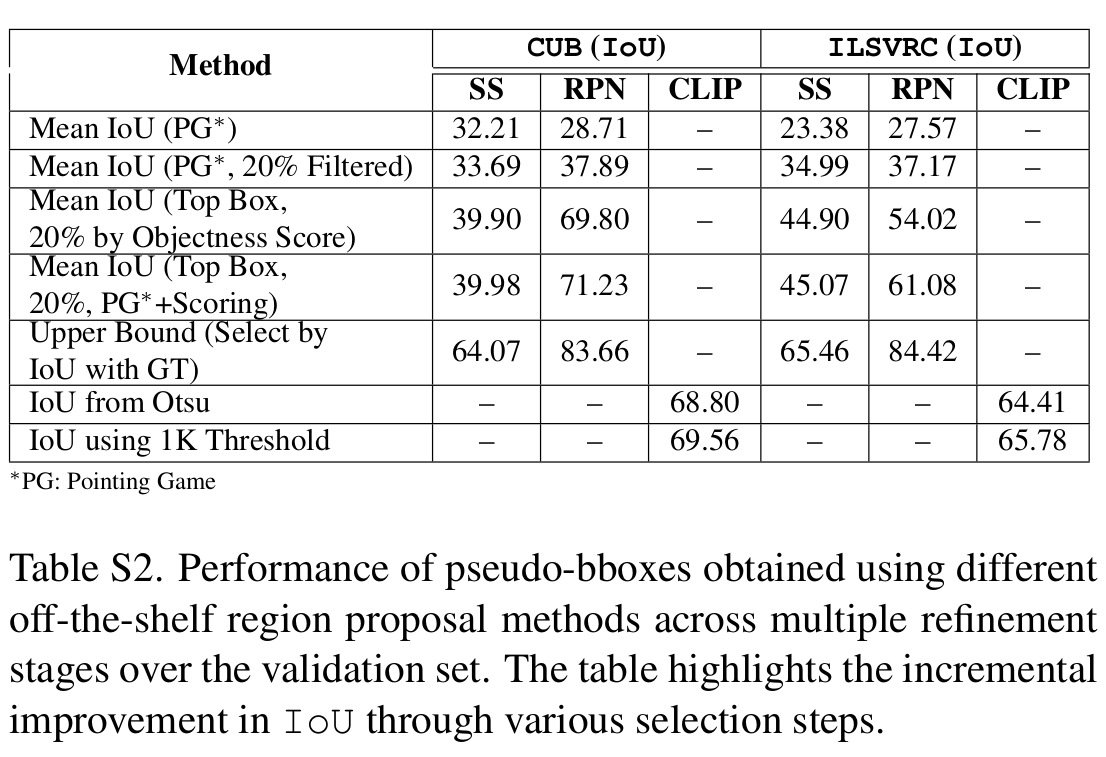
Quality of Pseudo-bbox Annotation
Model Selection with Noisy Ground Truth Bboxes
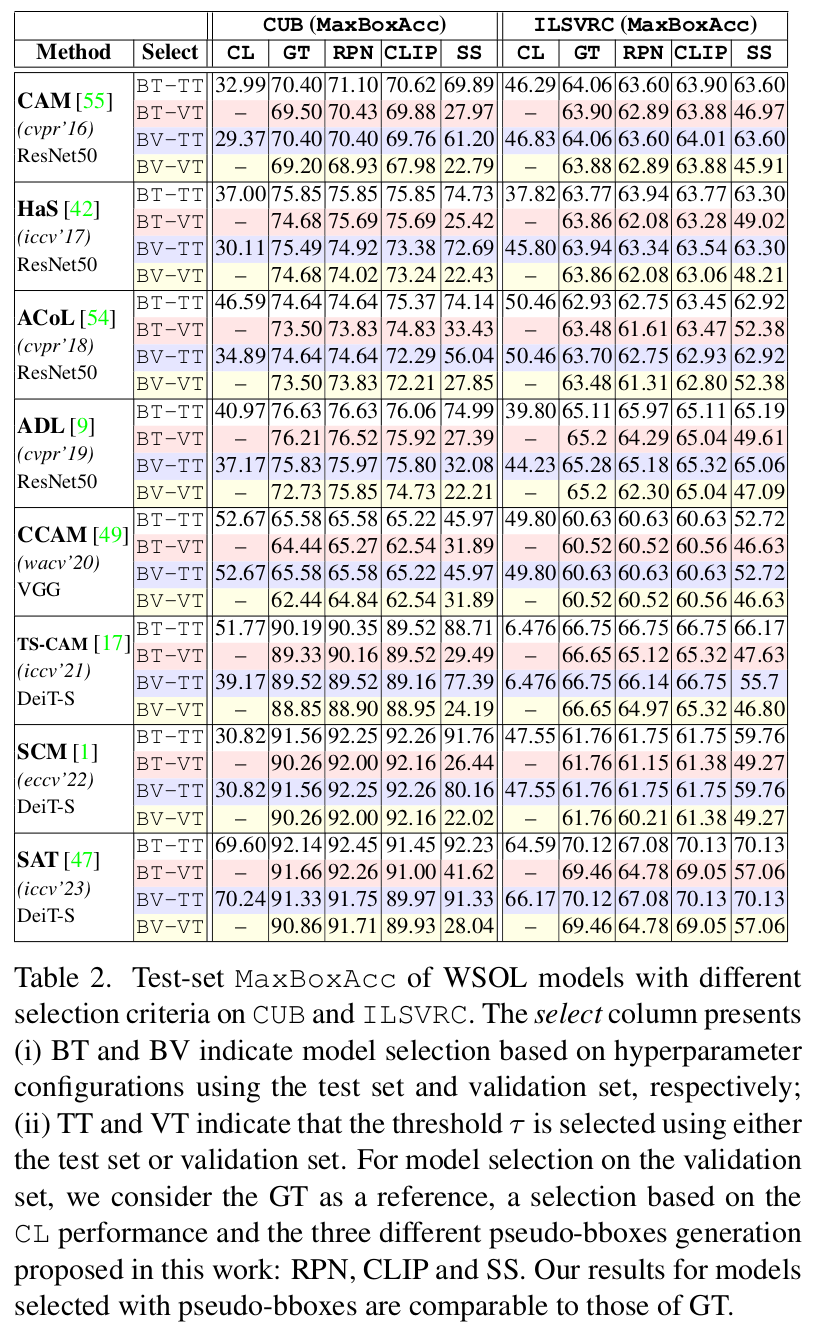
Results
Recommendation for Realistic Evaluation
In line with our proposed evaluation protocol and empirical results, we recommend the following practices. Training and evaluation should be constrained to only utilizing class-level labels without resorting to manual bbox annotations for model selection and threshold estimation:
- We recommend utilizing pseudo-bboxes generated by off-the-sheld methods for validation set. Our experiments show that these pseudo-bboxes can effectively provide the localization annotation for model selection, achieving performance comparable to using GT annotations.
- Estimating thresholds using pseudo-bboxes from the validation set instead of the test set to produce bboxes from localization maps. This approach addresses the unrealistic practice of thresholding.
- Our experiments suggest that model selection across various experiments, each employing different hyperparameters, should be based on the performance of pseudo-bboxes on the validation set. This approach mitigates bias in model performance evaluation.
- Be cautious when using thresholded-IOU metrics (IOU-30, IOU-50, IOU-70) and their variants, as these can mislead by considering uniform performance across instances above the set threshold. Our analysis reveals a non-linear relationship between thresholded-IOU and IOU (Tab.3). We recommend the use of non-thresholded-IOU for realistic evaluation.
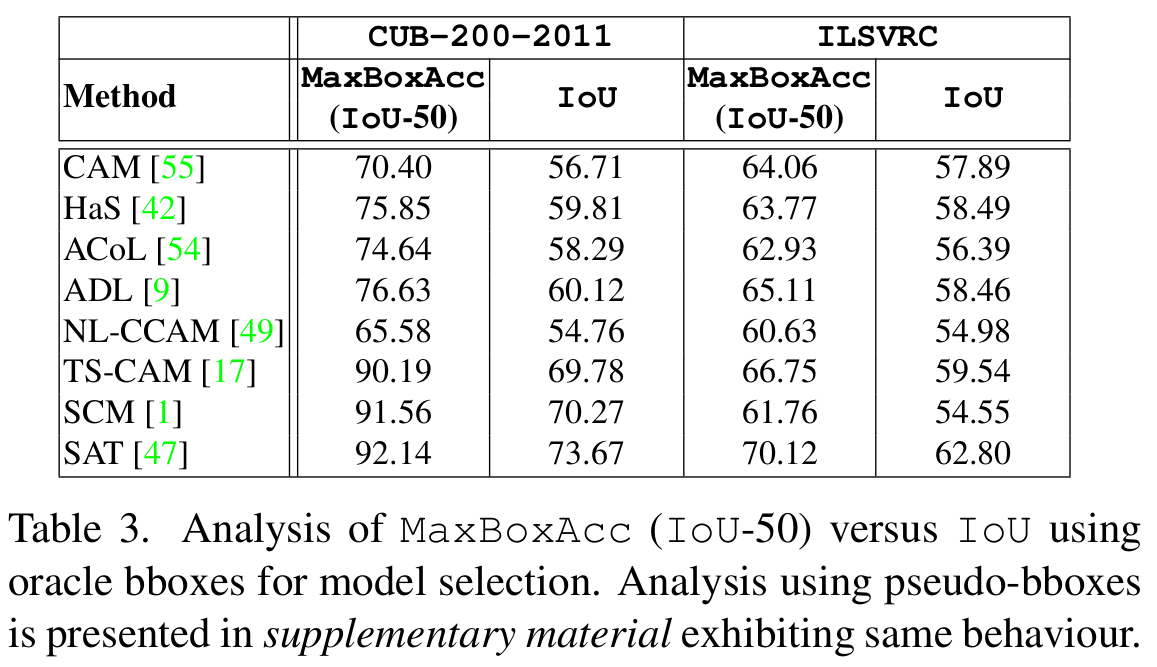
More Results

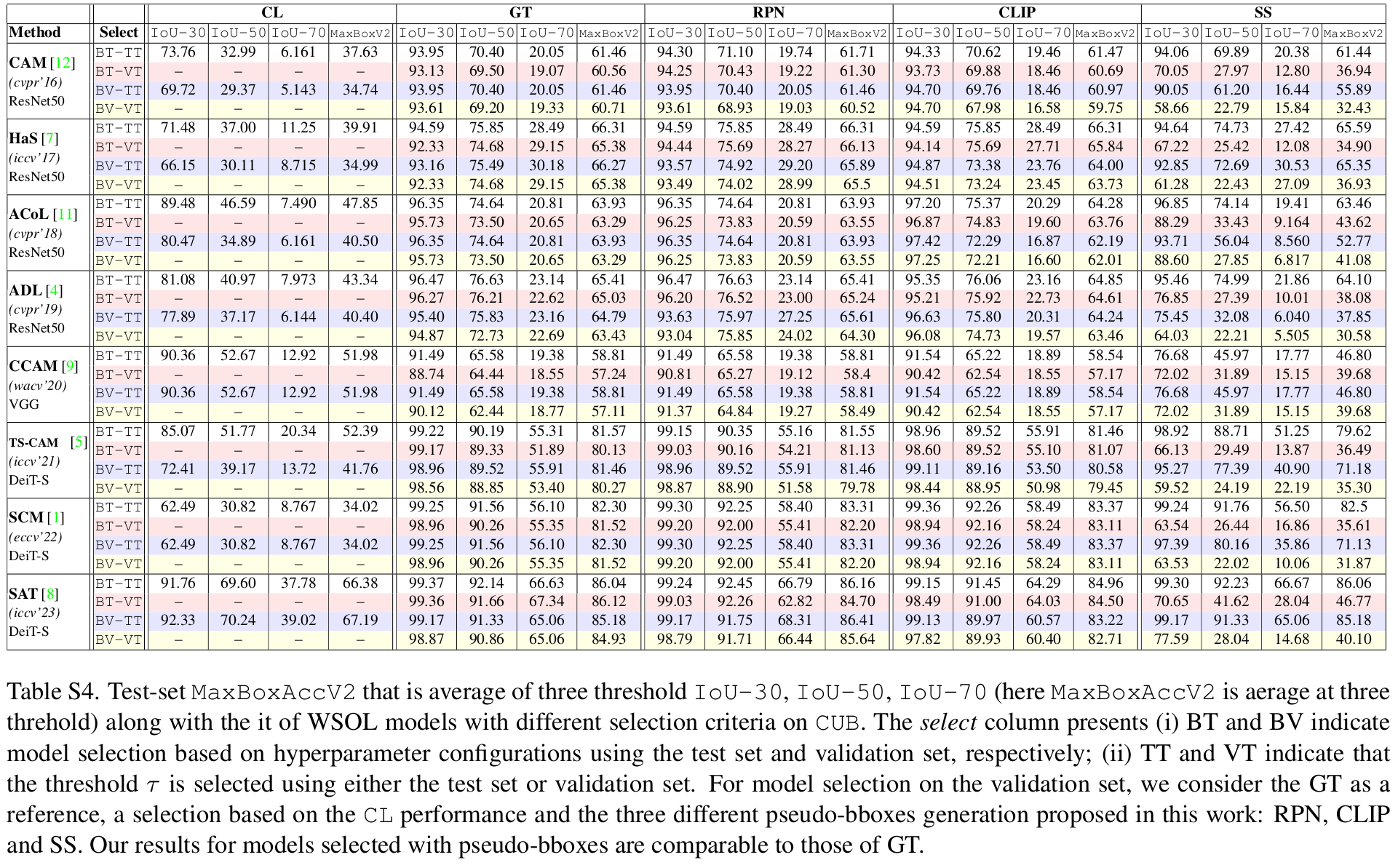
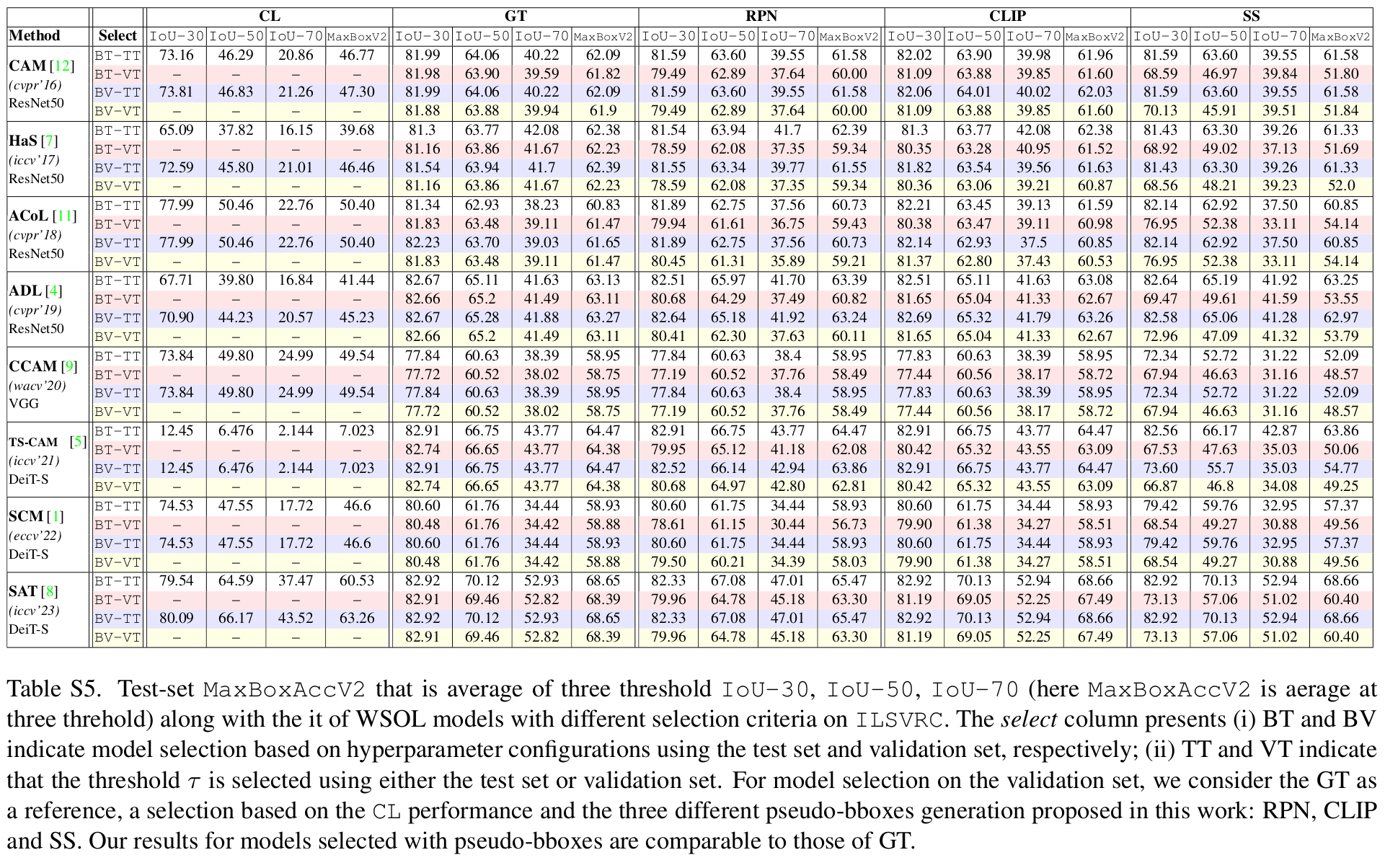
Conclusion
The currently-used protocol (Choe et al.) for evaluation of WSOL methods has driven significant progress in the field. However, its reliance on manually annotated bboxes during validation for model selection, and annotated test set for threshold estimation leads to an overestimation of localization performance on the test set. In this work, we propose generating pseudo-bboxes for the validation set using off-the-shelf pretrained region proposal models for both model selection and threshold estimation. This threshold is then employed to produce bboxes from localization maps on the test set. Our approach was evaluated with different WSOL methods and shows that employing pseudo-bboxes for model evaluation achieves localization performance comparable to models selected using GT bboxes where the threshold is estimated on the test set. Our approach is therefore a promising and more realistic alternative than using a GT annotated held-out dataset. Despite the promising results with our protocol, performing model selection in WSOL without localization annotation remains an open issue.
Acknowledgments
This research was supported in part by the Natural Sciences and Engineering Research Council of Canada, and the Digital Research Alliance of Canada.