
CoLo-CAM: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos (Pattern Recognition 2025)
by Soufiane Belharbi1, Shakeeb Murtaza1, Marco Pedersoli1, Ismail Ben Ayed1, Luke McCaffrey2, Eric Granger1
1 LIVIA, ILLS, Dept. of Systems Engineering, ETS Montreal, Canada
2 Goodman Cancer Research Centre, Dept. of Oncology, McGill University, Montreal, Canada
![]()
![]()
@article{belharbi2025colocam,
title="{CoLo-CAM}: Class Activation Mapping for Object Co-Localization in Weakly-Labeled Unconstrained Videos",
author="Belharbi, S. and Murtaza, S. and Pedersoli, M. and Ben Ayed, I. and
McCaffrey, L. and Granger, E.",
journal="Pattern Recognition",
volume="162",
pages="111358",
year="2025"
}
Abstract
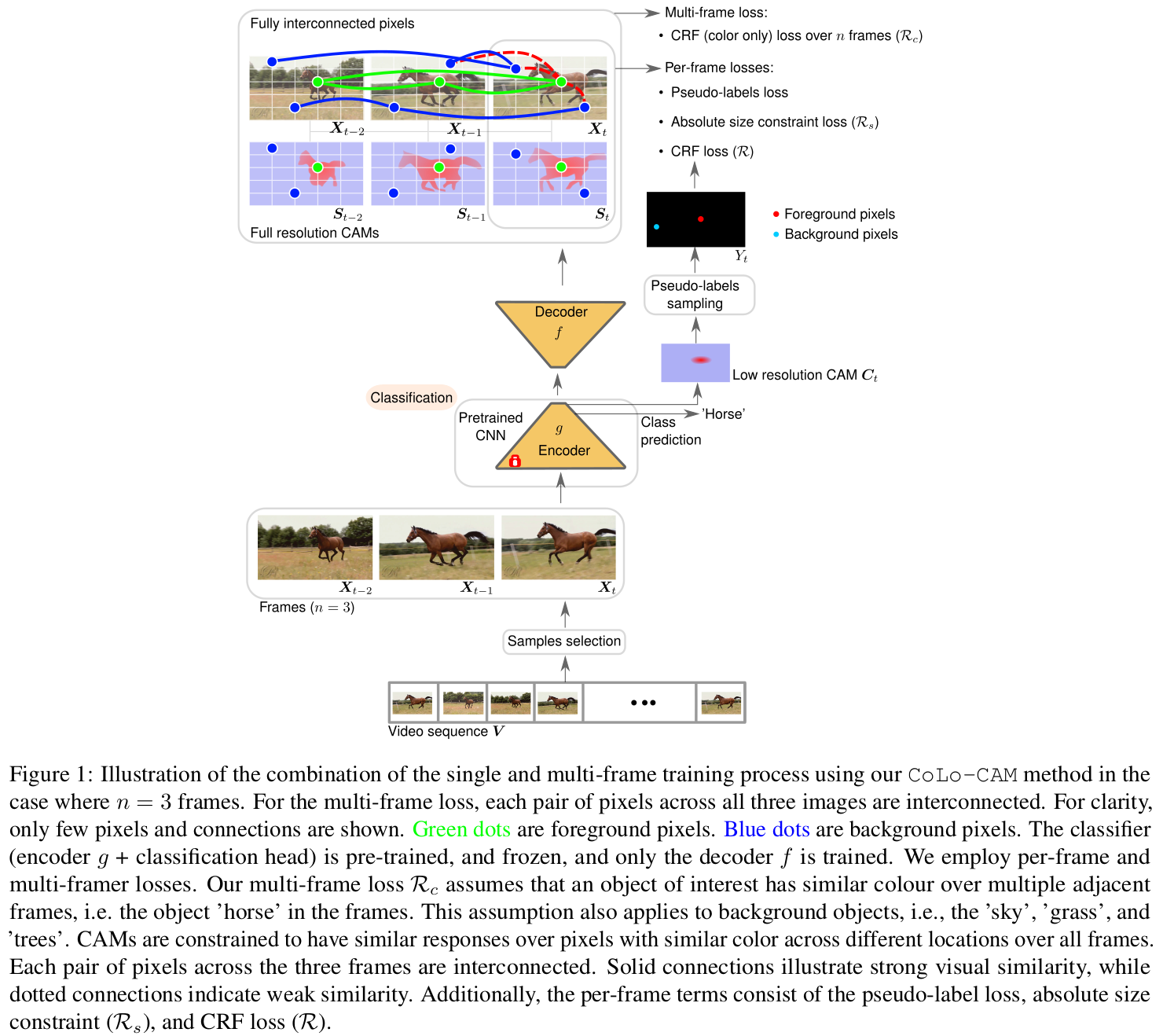
Leveraging spatiotemporal information in videos is critical for weakly supervised video object localization (WSVOL) tasks. However, state-of-the-art methods only rely on visual and motion cues, while discarding discriminative information, making them susceptible to inaccurate localizations. Recently, discriminative models have been explored for WSVOL tasks using a temporal class activation mapping (CAM) method. Although their results are promising, objects are assumed to have limited movement from frame to frame, leading to degradation in performance for relatively long-term dependencies. This paper proposes a novel CAM method for WSVOL that exploits spatiotemporal information in activation maps during training without constraining an object’s position. Its training relies on Co-Localization, hence, the name CoLo-CAM. Given a sequence of frames, localization is jointly learned based on color cues extracted across the corresponding maps, by assuming that an object has similar color in consecutive frames. CAM activations are constrained to respond similarly over pixels with similar colors, achieving co-localization. This improves localization performance because the joint learning creates direct communication among pixels across all image locations and over all frames, allowing for transfer, aggregation, and correction of localizations. Co-localization is integrated into training by minimizing the color term of a conditional random field (CRF) loss over a sequence of frames/CAMs. Extensive experiments on two challenging YouTube-Objects datasets of unconstrained videos show the merits of our CoLo-CAM method, and its robustness to long-term dependencies, leading to new state-of-the-art performance for WSVOL task. Our code is publicly available: github.com/sbelharbi/colo-cam.
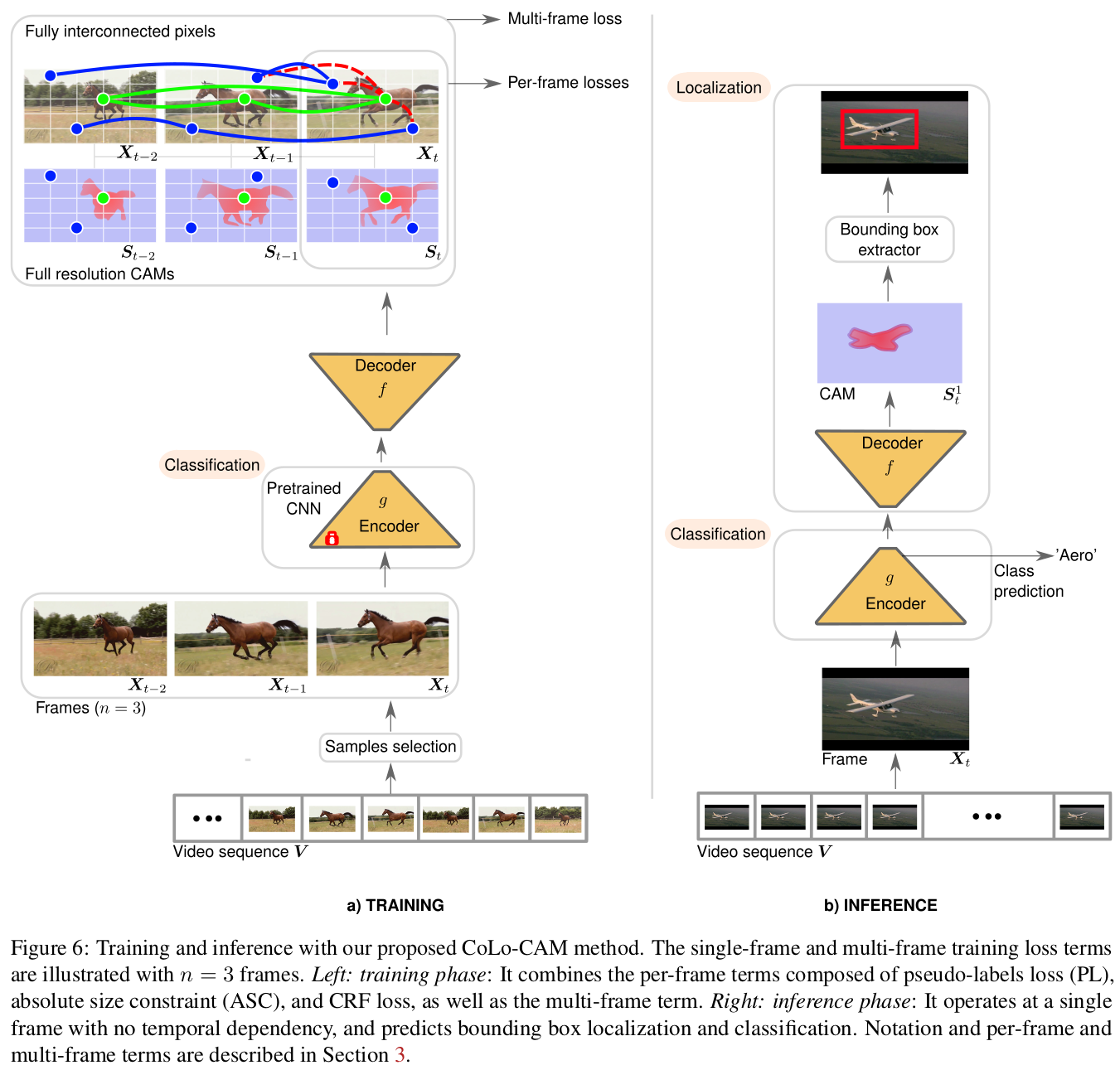
Proposed Method
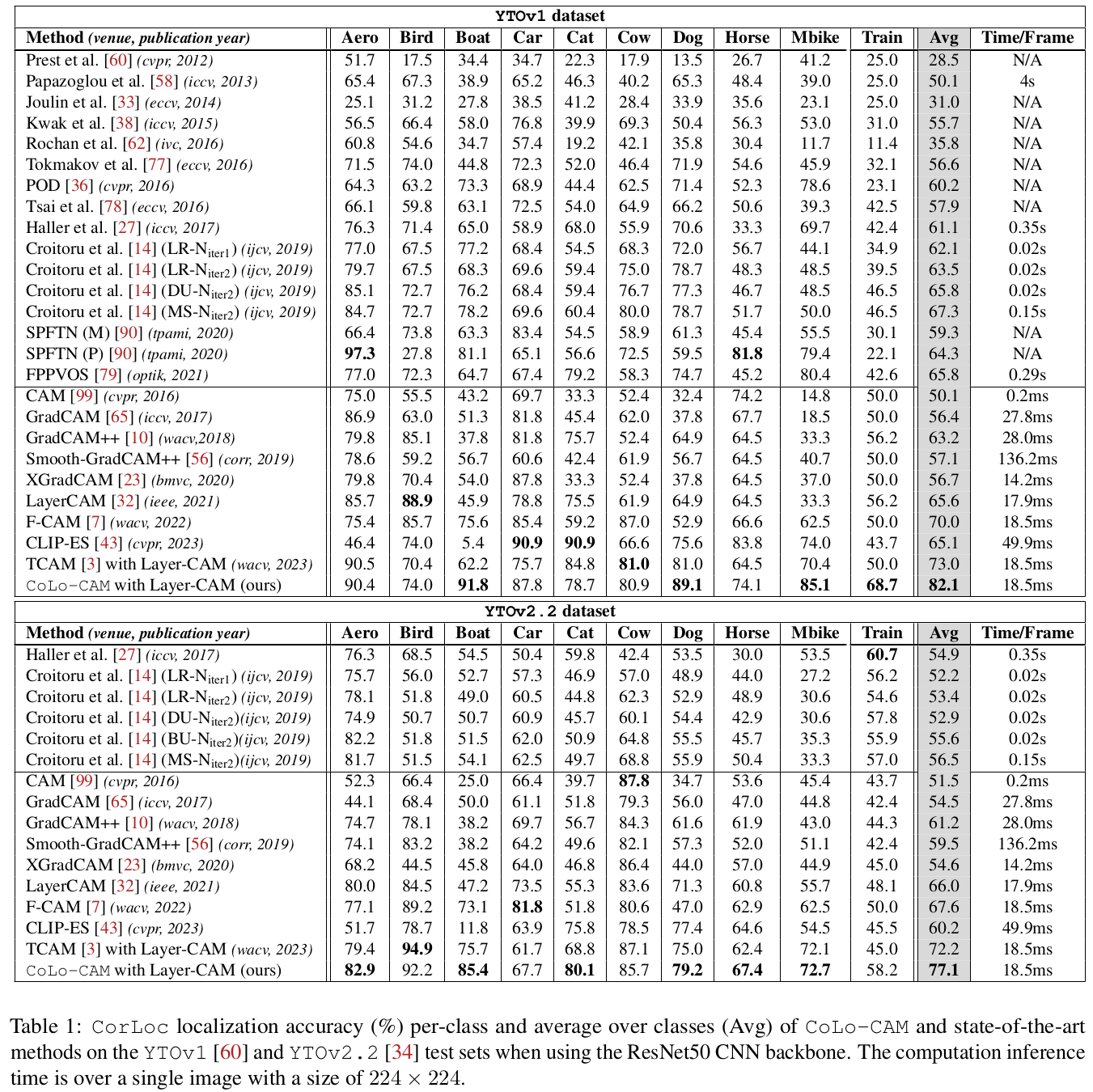
Results
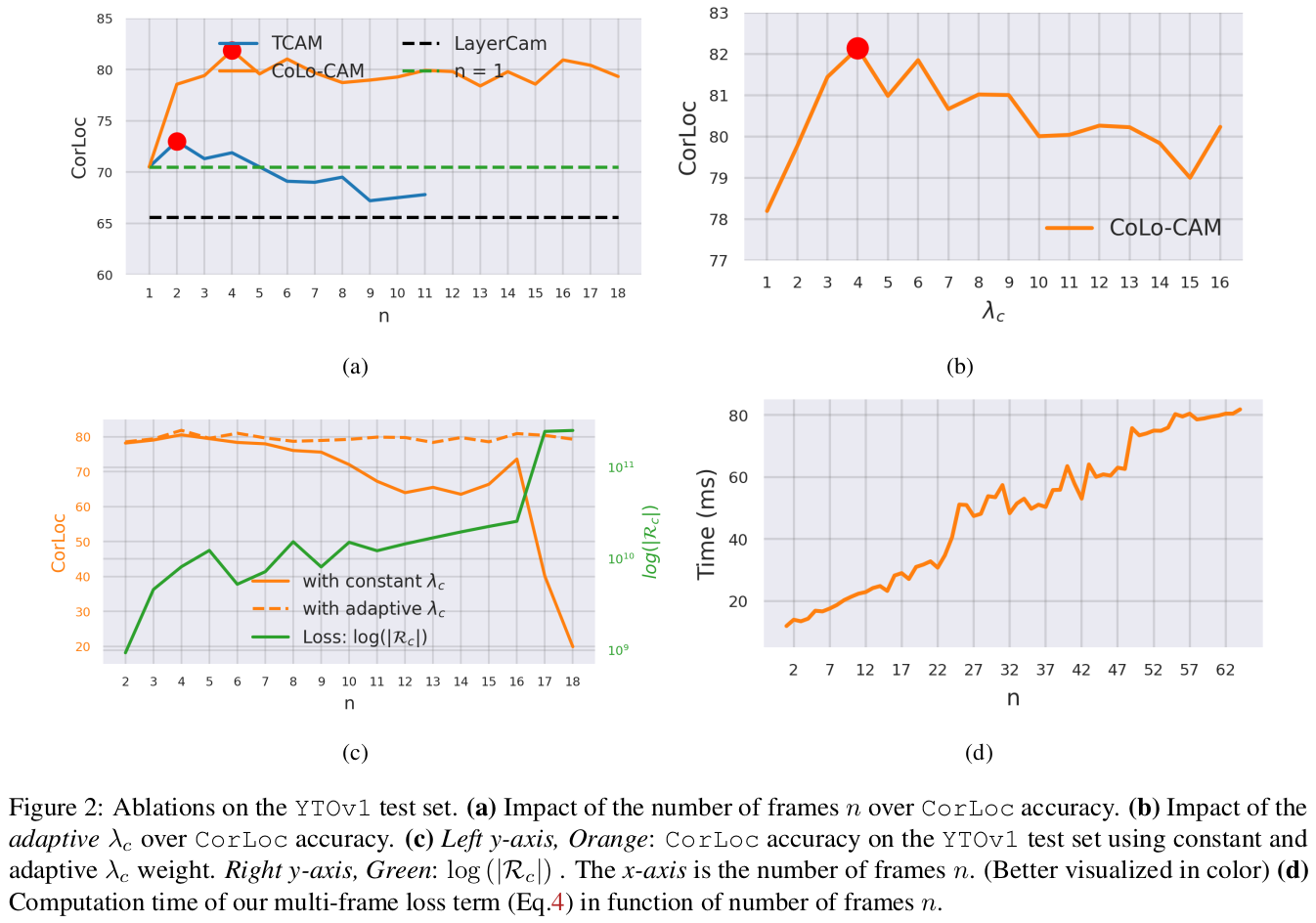
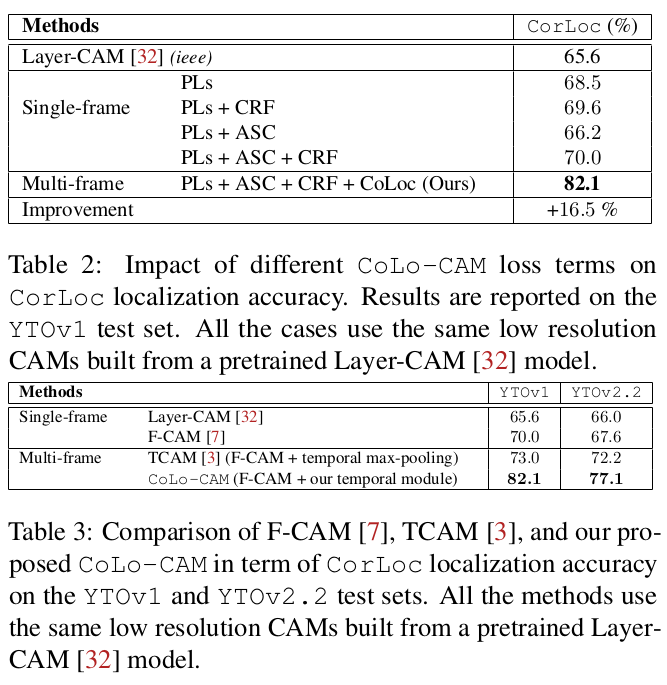
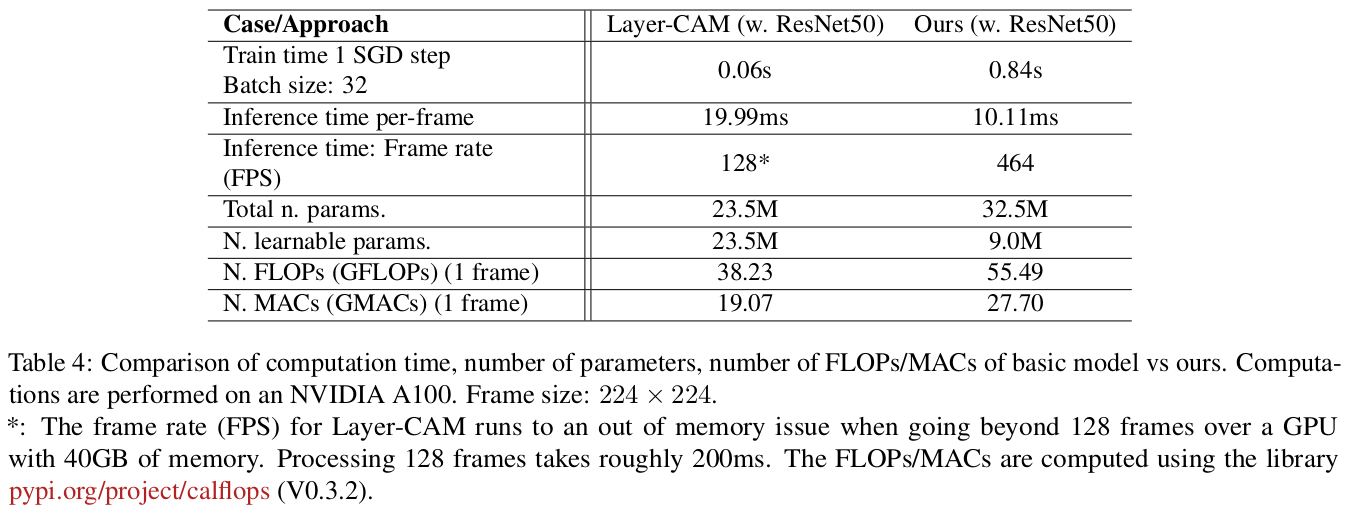
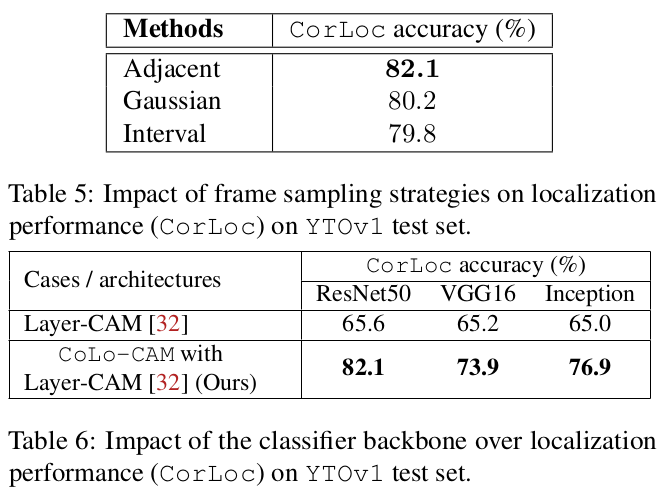
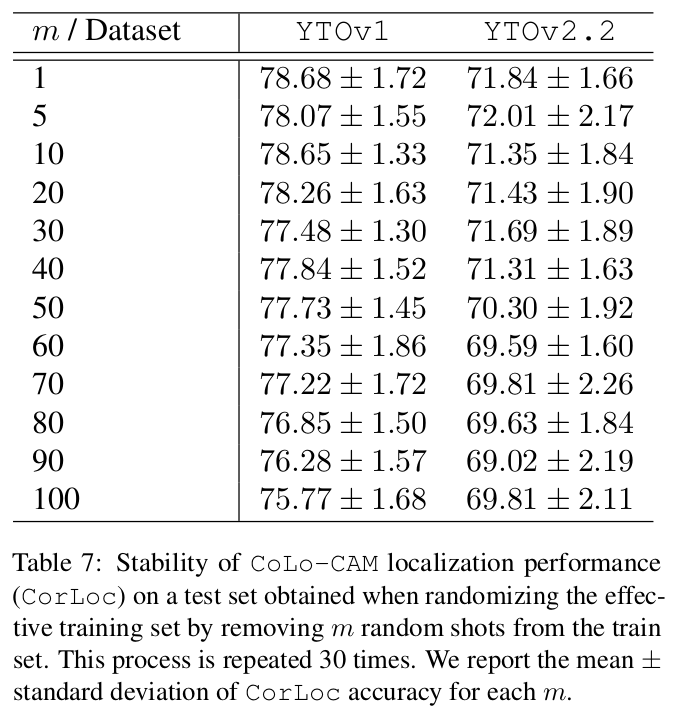
Ablations
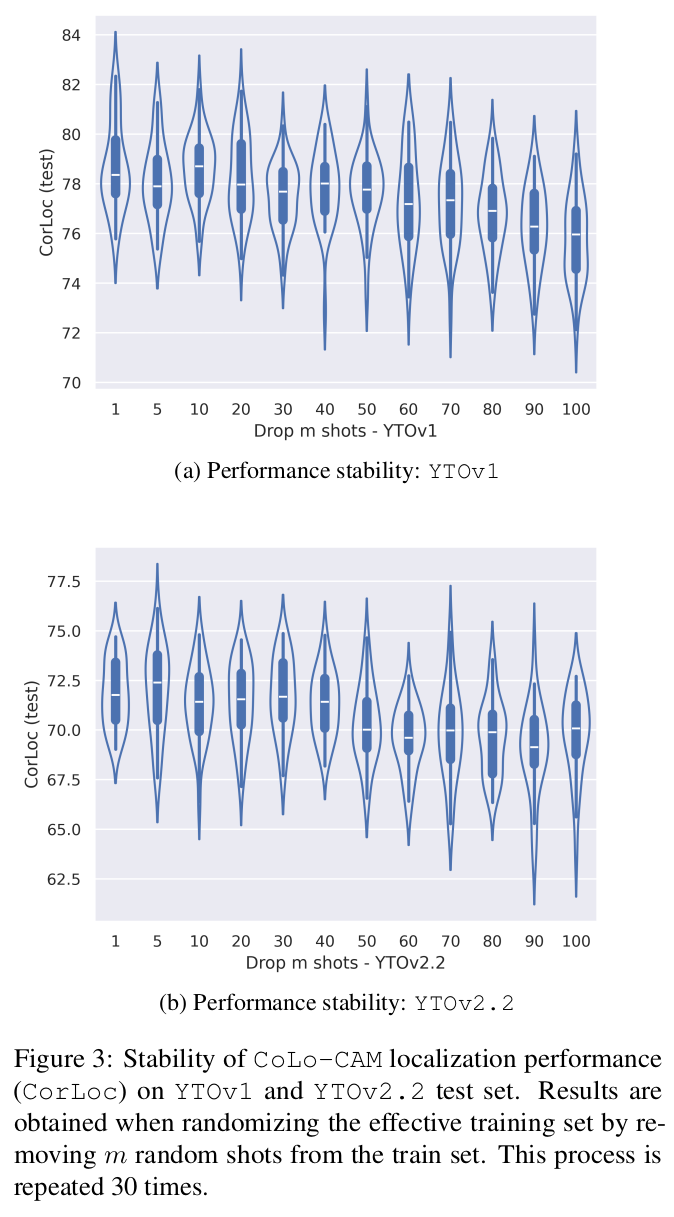
Visual Results


More Visual Demonstration
More demo: here.
Conclusion
This paper proposes a new CAM-based approach for WSVOL by introducing co-localization into a CAM-based method. Using pixel-color cue, our proposed CoLo-CAM method constrains CAM responses to be similar over visually similar pixels across all frames, achieving col-localization. Our total training loss comprises per-frame and multi-frame terms optimized simultaneously via standard Stochastic Gradient Descent (SGD). Empirical experiments showed that our produced CAMs become more discriminative. This translates into several advantageous properties: sharp, more complete, and less noisy activations localized more precisely around objects. Moreover, localizing small/large objects becomes more accurate. Additionally, our method is more robust to training with long time-dependency and leads to new state-of-the-art localization performance.
Despite its improvements, our method still holds some limitations. Our pixel pseudo-labels are less accurate since they come from a pretrained classifier. In particular, a major issue is the set of frames without object of interest in a video. In WSVOL, it is typically assumed that the video label transfers to each frame. However, in unconstrained videos, not all frames hold the labeled object. Therefore, the label is mistakenly transferred into empty frames. This furthermore allows the classifier to suggest relevant ROIs in such frames leading to more errors in training. One possible way to alleviate this issue is to leverage the per-class probabilities of the classifier to assess whether an object is present or not in a frame. Such likelihood can be exploited to discard frames or weight loss terms over them.
Another issue is related to inference that is performed frame by by frame without leveraging temporal information in a video. The negative impact of this can be observed over a sequence of predictions which are characterized by localization inconsistencies. This is illustrated by large shift in localization where the bounding box (and the CAM activation), moves abruptly from one location at a frame to completely different location at the next frame. Prediction without accounting for temporal dependencies can easily lead to such results. Future works may consider improving the inference procedure by leveraging spatiotemporal information at the expense of inference time.
We note that our method can use either CNN- or transformer-based architecture. The only requirement is that the architecture is able to perform both tasks: classification and localization. A vision transformer-based (ViT) model can be employed as an encoder. A standard classification head can be used to perform classification task. A new localization head is required to replace our decoder to perform localization task. An architecture similar to the one presented in this work can be used in our work which is expected to yield better performance compared to CNN-based model as reported in their work. We leave this aspect for future work.
Acknowledgments
This research was supported in part by the Canadian Institutes of Health Research, the Natural Sciences and Engineering Research Council of Canada, and the Digital Research Alliance of Canada.