
BAH Dataset for Ambivalence/Hesitancy Recognition in Videos for Digital Behavioural Change (ICLR2026)
by Manuela González-González3,4, Soufiane Belharbi1, Muhammad Osama Zeeshan1, Masoumeh Sharafi1, Muhammad Haseeb Aslam1, Alessandro Lameiras Koerich2, Marco Pedersoli1, Simon L. Bacon3,4, Eric Granger1
1 LIVIA, Dept. of Systems Engineering, ETS Montreal, Canada
2 LIVIA, Dept. of Software and IT Engineering, ETS Montreal, Canada
3 Dept. of Health, Kinesiology, & Applied Physiology, Concordia University, Montreal, Canada
4 Montreal Behavioural Medicine Centre, CIUSSS Nord-de-l’Ile-de-Montréal, Canada
Contact: 
![]()
![]()


@inproceedings{gonzalez-26-bah,
title="{BAH} Dataset for Ambivalence/Hesitancy Recognition in Videos for Digital Behavioural Change",
author="González-González, M. and Belharbi, S. and Zeeshan, M. O. and Sharafi, M. and Aslam, M. H and Pedersoli, M. and Koerich, A. L. and Bacon, S. L. and Granger, E.",
booktitle={ICLR},
year={2026}
}
Abstract
Ambivalence and hesitancy (A/H), closely related constructs, are the primary
reasons why individuals delay, avoid, or abandon health behaviour changes.
They are subtle and conflicting emotions that sets a person in a state between
positive and negative orientations, or between acceptance and refusal to do
something. They manifest as a discord in affect between multiple modalities or
within a modality, such as facial and vocal expressions, and body language.
Although experts can be trained to recognize A/H as done for in-person
interactions, integrating them into digital health interventions is costly and
less effective. Automatic A/H recognition is therefore critical for the
personalization and cost-effectiveness of digital behaviour change
interventions. However, no datasets currently exist for the design of machine
learning models to recognize A/H.
This paper introduces the Behavioural Ambivalence/Hesitancy (BAH) dataset
collected for multimodal recognition of A/H in videos. It contains 1,427 videos
with a total duration of 10.60 hours, captured from 300 participants across
Canada, answering predefined questions to elicit A/H.
It is intended to mirror real-world digital behaviour change interventions
delivered online. BAH is annotated by three experts to provide timestamps that
indicate where A/H occurs, and frame- and video-level annotations with A/H
cues. Video transcripts, cropped and aligned faces, and participant metadata are
also provided. Since A and H manifest similarly in practice, we provide a binary
annotation indicating the presence or absence of A/H.
Additionally, this paper includes benchmarking results using baseline models on
BAH for frame- and video-level recognition, zero-shot prediction, and
personalization with source-free domain adaptation methods. The limited
performance highlights the need for adapted multimodal and spatio-temporal
models for A/H recognition. Results obtained with specialized fusion methods are
shown to assess the presence of conflicts between modalities, additionally
temporal modelling for within-modality conflicts are essential for more
discriminant A/H recognition.
The data, code, and pretrained weights are publicly available:
github.com/sbelharbi/bah-dataset.
License / Download
THIS BAH DATASET IS LICENSED UNDER PROPRIETARY LICENSE FOR RESEARCH ONLY. TO REQUEST THE DATASET PLEASE FOLLOW THESE INSTRUCTIONS: BAH-DATSET-REQUEST.
BAH: Capture & Annotation
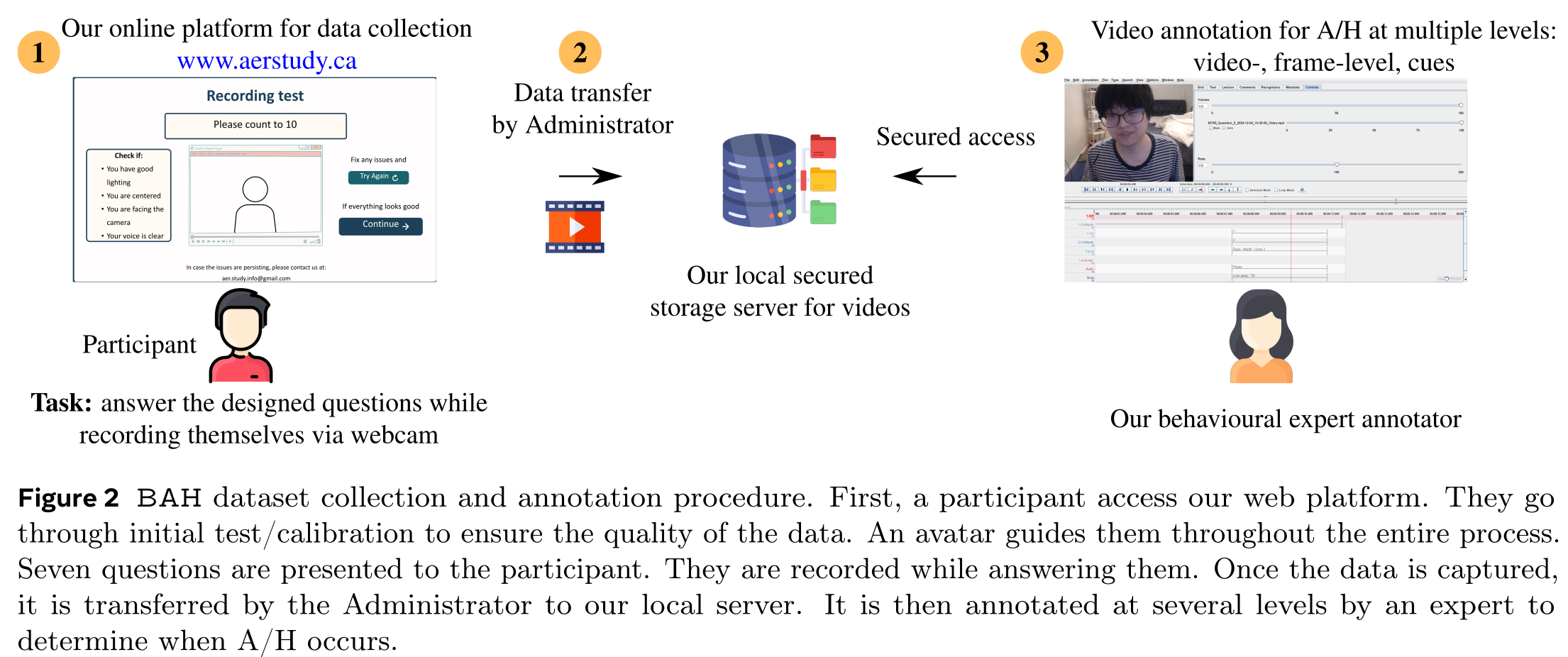

BAH: Variability
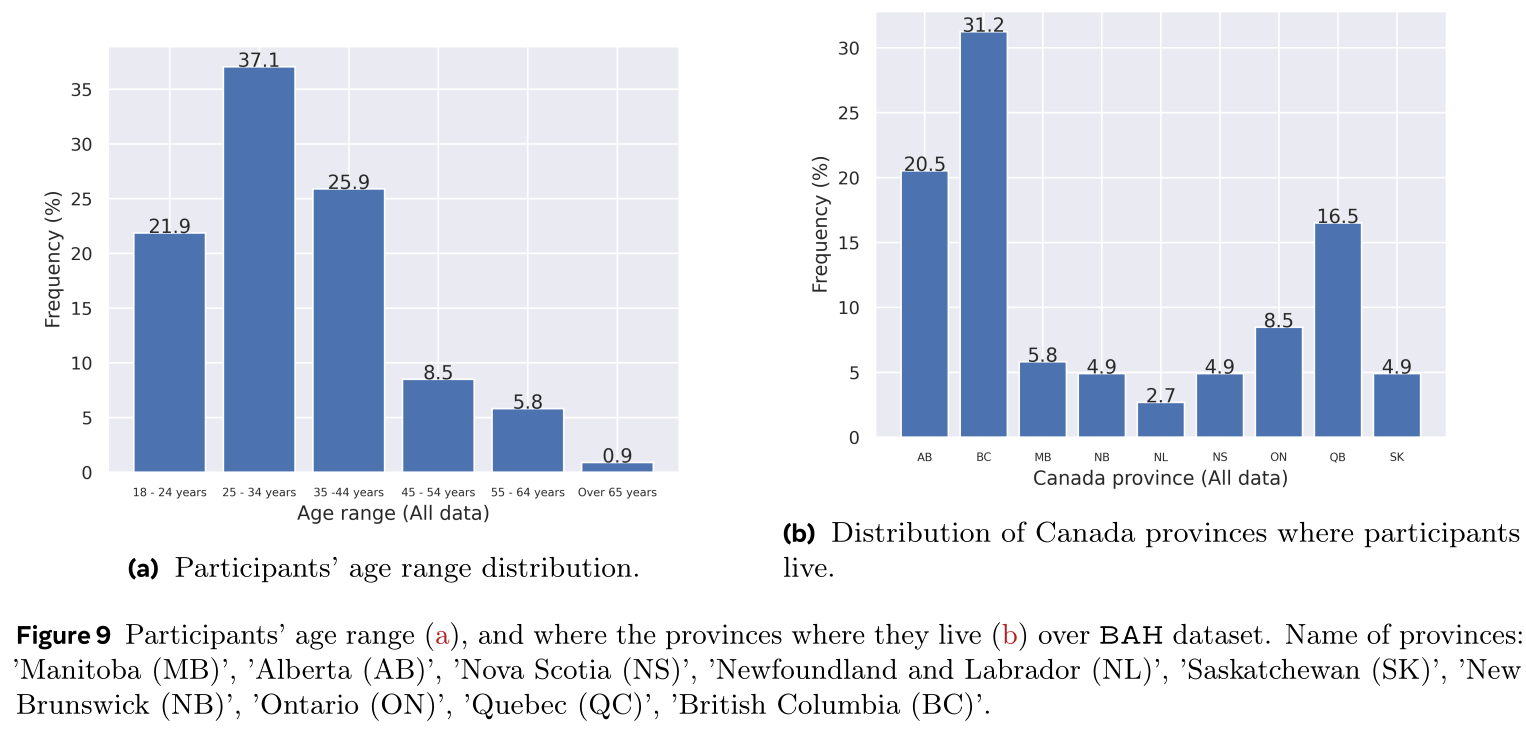
The dataset is designed to approximate the demographic distribution of sex and provincial representation in Canada. The BAH dataset is composed of 300 participant across Canada from nine provinces where 25.7% of participants is from British Columbia followed by Alberta with 19.7% and Ontario with 17.3%.
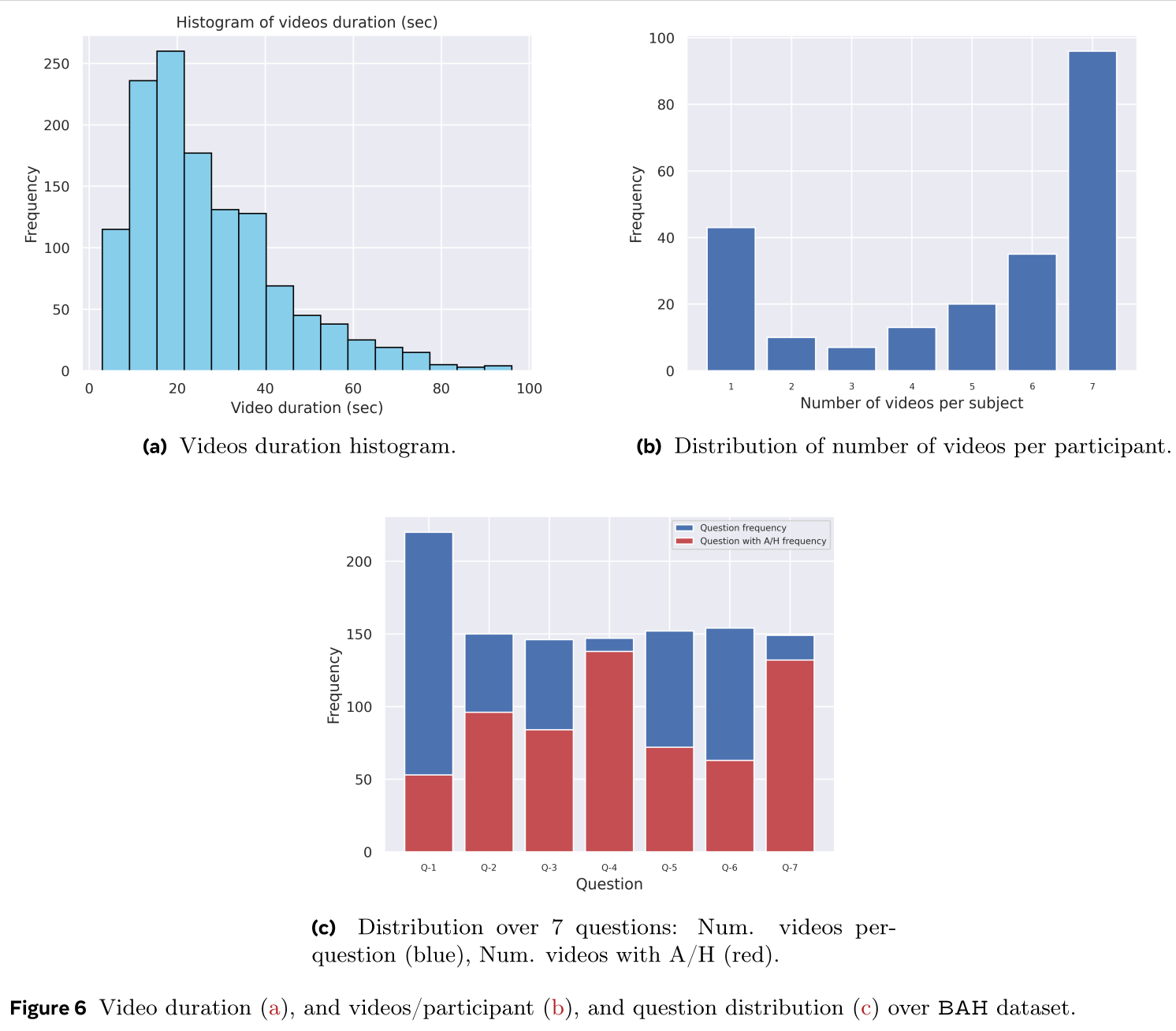
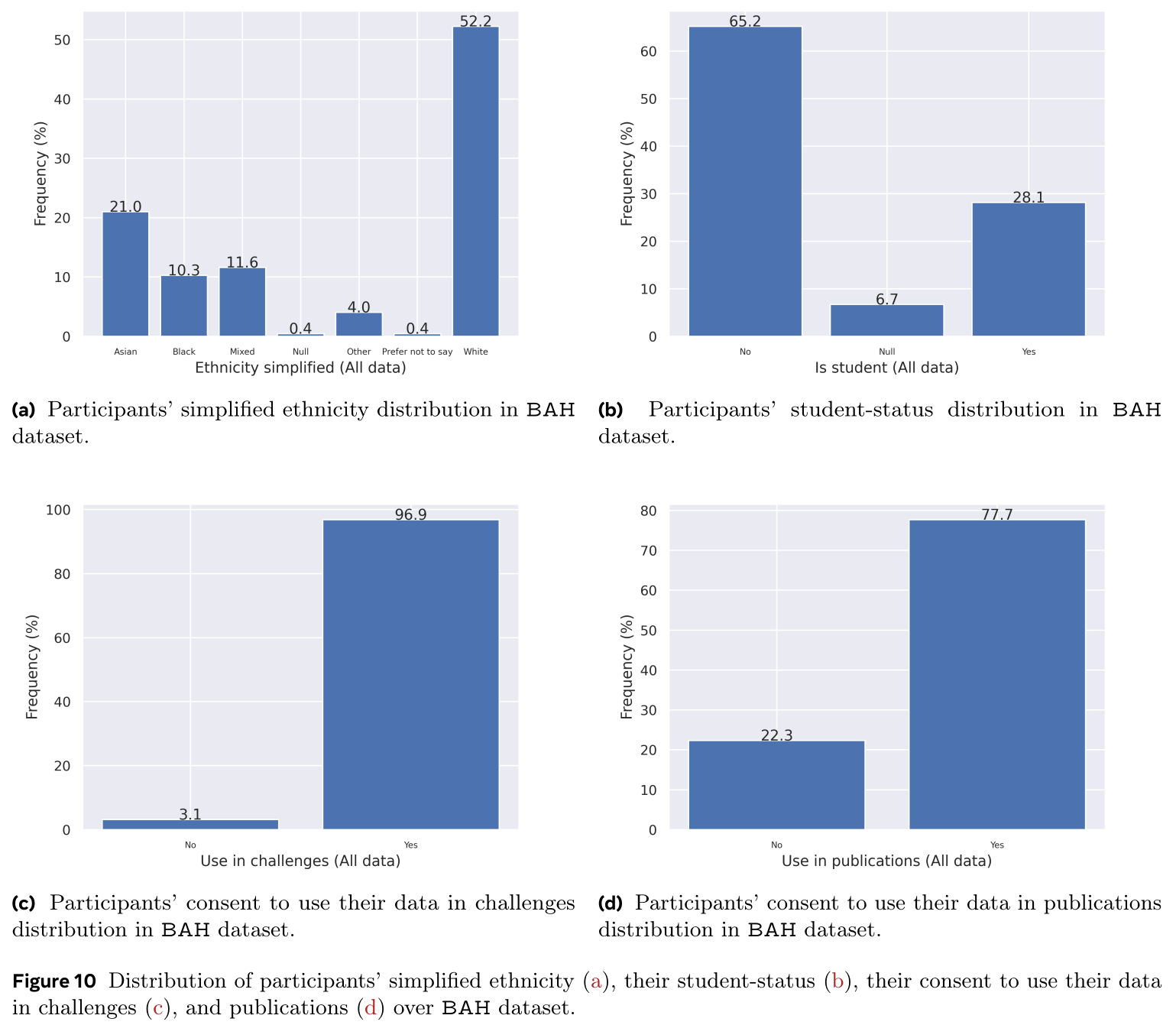
All participants agreed to be part of this dataset. However, 61 participants (20.3%) did not consent to be in publications while only seven participants (2.3%) did not consent to be part of challenges. The recorded videos are majority in English language and very few are in French language. Each participant can record up to seven videos where 113 participants have recorded the full seven videos. We obtained an average of ${\sim4.75}$ videos/participant where each participant has an average of ${\sim2.59}$ videos with A/H which is equivalent to ${\sim520.85}$ frames of A/H (or $\sim21.49$ seconds of A/H). The dataset amounts a total of 1,427 videos (${\sim10.60}$ hours) where 778 videos contain A/H (${\sim 1.79}$ hours). This amounts to 916,618 total frames where 156,255 contain A/H. Since captured videos represent answers to questions, they are relatively short. BAH dataset has an average video duration of ${26.76 \pm 16.47}$ (seconds) with a minimum and maximum duration of 3 and 96 seconds.
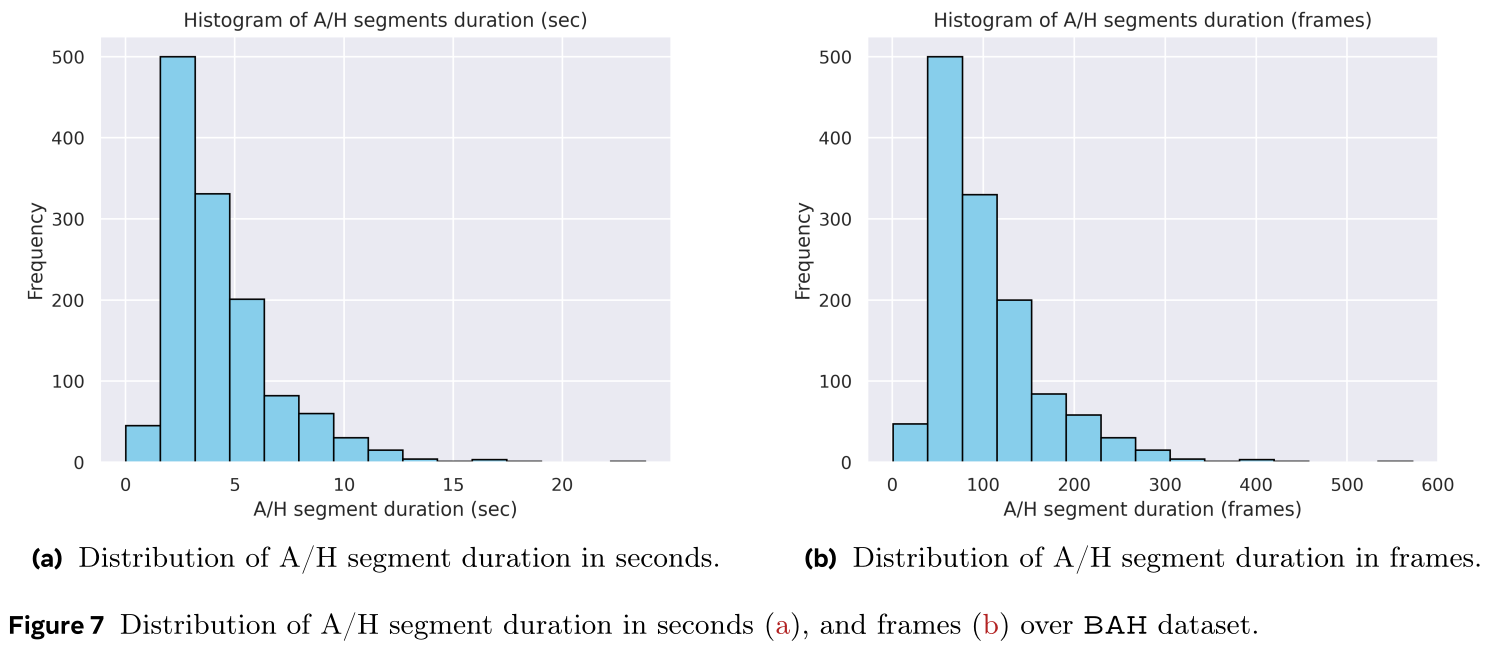
An important characteristic of this dataset is the duration of the A/H segments in videos. BAH counts a total of 443 videos with multiple A/H segments and 332 videos with only one A/H segment. In total, there are 1,504 A/H segments. In particular, the duration of segments varies but it is brief with an average of ${4.29 \pm 2.45}$ seconds which is equivalent to ${103.89 \pm 58.70}$ frames. The minimum and maximum A/H segment is 0.004 seconds (1 frame), and 23.8 seconds (572 frames), respectively.
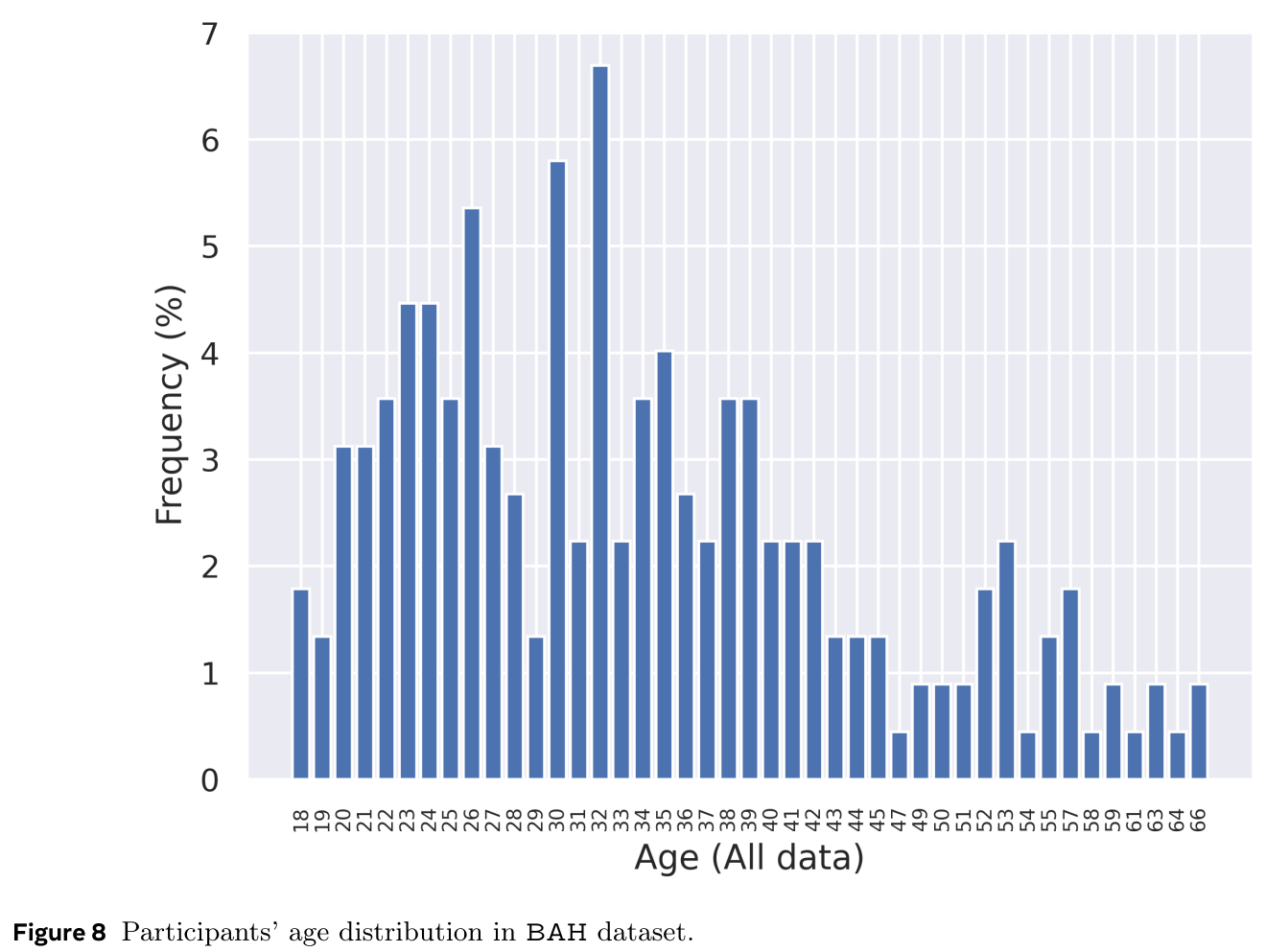
In terms of participants age, the dataset covers a large range from 18 to 74 years old. In particular, 37.7% of the participants covers the range 25-34 years, followed by the range of 35-44 years with 24.3%, then the range of 18-24 with 20.7%. In terms of sex, 52.0% are female, while 47.3 are male. As for ethnicity variation, White comes with 54.0% of the participants, followed by Asian with 21.0%, and Mixed with 10.7%, then Black with 9.7%. Large part of the participants are not students (67.0%) which limits common issues in recruit bias.
The public BAH dataset contains the row videos, detailed A/H annotation at video- and frame-level, cues, and per participant demographic information including age, birth country, Canada province where the participant lives, ethnicity, ethnicity simplified, sex, student status, consent to use recordings in publications. More details about the dataset diversity are provided in the appendix of the paper.
BAH: Experimental Protocol
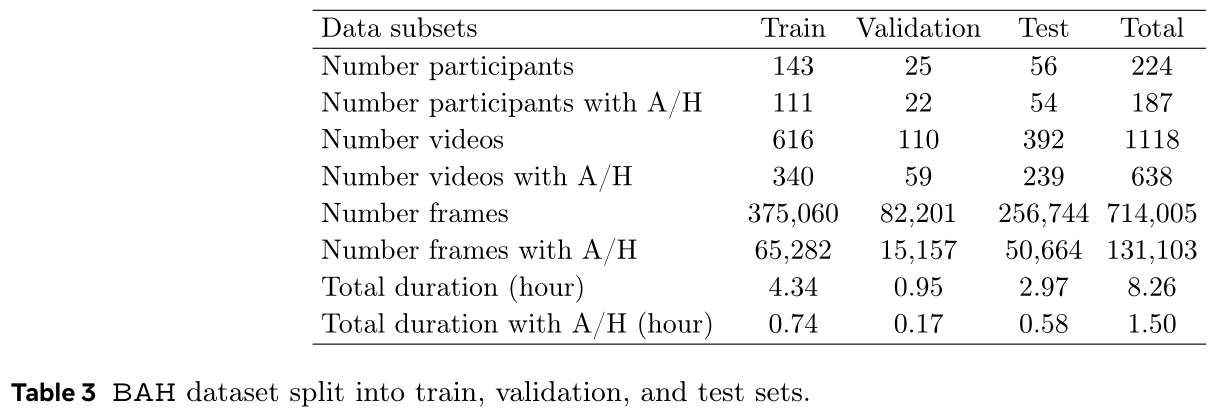
Dataset split. The dataset is divided randomly based on participants into 3 sets: train (195 participants), validation (30 participants) and test (75 participants) set. We ensured that the 3 splits represent the total data distribution. The train and validation sets amounts to 3/4 of the total participants, while 1/4 goes to the test set. Videos of one participants belong to one and one set only. The details of each set is presented in the following tables. The split files are provided along with the dataset files. They contain the split in terms of videos and frames ready to use. Note that the dataset is highly imbalanced, especially at frame level where only 17.04% contains A/H. This factor should be accounted for during training and evaluation. The dataset can be used for training at video- and/or frame-level. The participant identifiers are provided in the splits allowing subject-based learning scenarios.
Evaluation metrics. We refer here to the positive class as the class with label 1 indicating the presence of A/H, while negative class is the class 0 indicating the absence of A/H. To account for the imbalance in BAH dataset, we use adapted standard evaluation metrics: - Average F1 (WF1) score which is the unweighted mean of F1 of the positive and negative class. - Average precision score (AP) of the positive class which accounts for the performance sensitivity to the model’s confidence. For AP score, a threshold list between 0 and 1 is used with a step of 0.001. Evaluation code of all measures is provided along with the public code of this dataset.

Experiments: Baselines
1) Frame-level supervised classification using multimodal
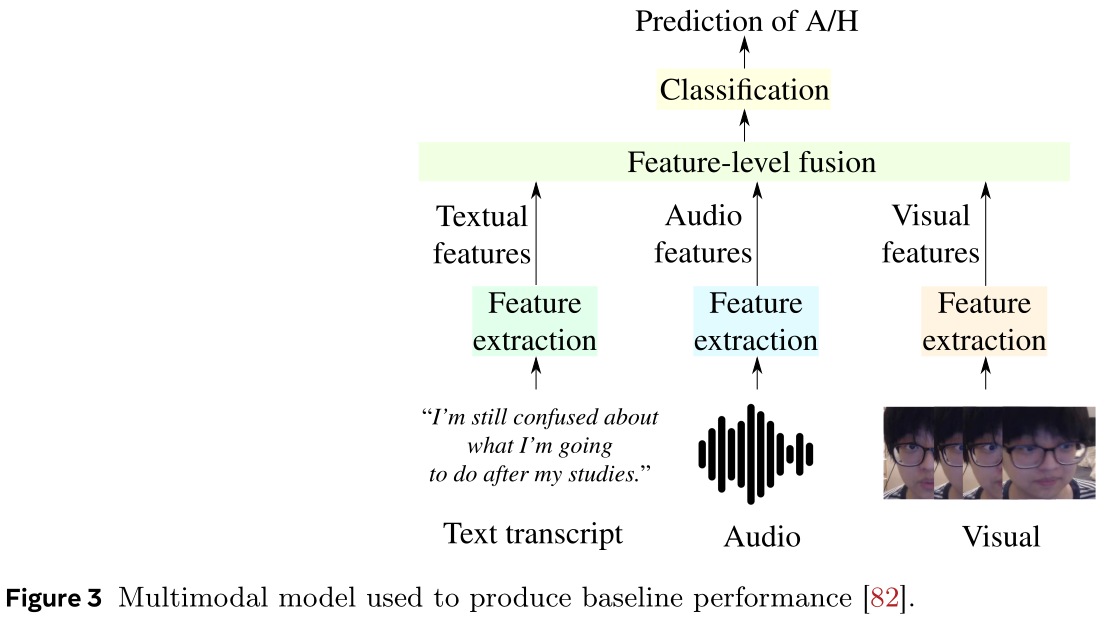


2) Video-level supervised classification using multimodal

3) Zero-shot performance: Frame- & video-level


4) Personalization using domain adaptation (frame-level)

Conclusion
This paper introduces BAH, a new multimodal and participant-based dataset for A/H recognition in videos. It contains the videos of 300 recruited participants captured across 9 provinces in Canada. Participants recorded themselves using a webcam and a microphone through our web-platform while they answered 7 questions designed to elicit A/H.
The dataset amounts to 1,427 videos for a total duration of 10.60 hours, with 1.79 hours of A/H. It was annotated by our behavioural science team at the video- and frame-level. Our initial benchmarking study yields limited performance, highlighting the difficulty of A/H recognition. Results also indicate that leveraging context, multimodality, domain adaptation and adaptive feature fusion are promising directions to improve the accuracy and robustness of ML models on BAH. Our dataset and code are made public.
The appendix contains related work, more detailed and relevant statistics about the datasets and its diversity, dataset limitations, implementation details, and additional results.
Acknowledgments
This work was supported in part by the Fonds de recherche du Québec – Santé, the Natural Sciences and Engineering Research Council of Canada, Canada Foundation for Innovation, and the Digital Research Alliance of Canada. We thank interns that participated in the dataset annotation: Jessica Almeida (Concordia University, Université du Québec à Montréal), and Laura Lucia Ortiz (MBMC).